20221020
12일 차


앞서 포스팅한 Numpy는 전체 배열 원소를 동일한 타입으로 제한했다면
Pandas는 여러 형태의 데이터타입을 원소로 사용할 수 있다.

Pandas의 자료형은 Series로 불리며
Series는 1차원 배열과 유사한 자료형 형태로 만들어 진다.
Numpy의 행과 같은 느낌으로 Series는 Index를 가지고 있으며
기본값은 0부터 1씩 증가하는 숫자로 지정된다.

Numpy와 같이 Pandas 또한 import 시키고
as " " 로 명령어를 바꿀 수 있다.
Series생성은 pd.Series()로 생성한다.


숫자 10을 데이터로 가지고 있는 Series를 생성하면
0번 인덱스에 10이 있고 10의 데이터타입은 int라고 출력된다.

인덱싱이나 슬라이싱으로 값을 출력할 수 있으며
.values로 저장된 값을 확인할 수 있다.
.index로 원하는 Series에 인덱스가 몇 번부터 몇 번까지 있는지 확인할 수 있다.
* 숫자, 문자, 리스트, 딕셔너리 등등 모두 같은 방식으로 확인 가능

* 값에 한 가지 종류의 데이터만 들어갈 필요가 없다.(Numpy와 다른점)

딕셔너리 형태의 Series는 값을 확인하면 딕셔너리의 'value' 값이 나온다.


인덱스명의 변경을 위해선
.index = [ ] 을 사용하면 된다.
* 인덱스 명의 개수는 인덱스 개수와 같아야 한다.
* 단일 라벨 인덱스만 수정하는것은 불가능하다.
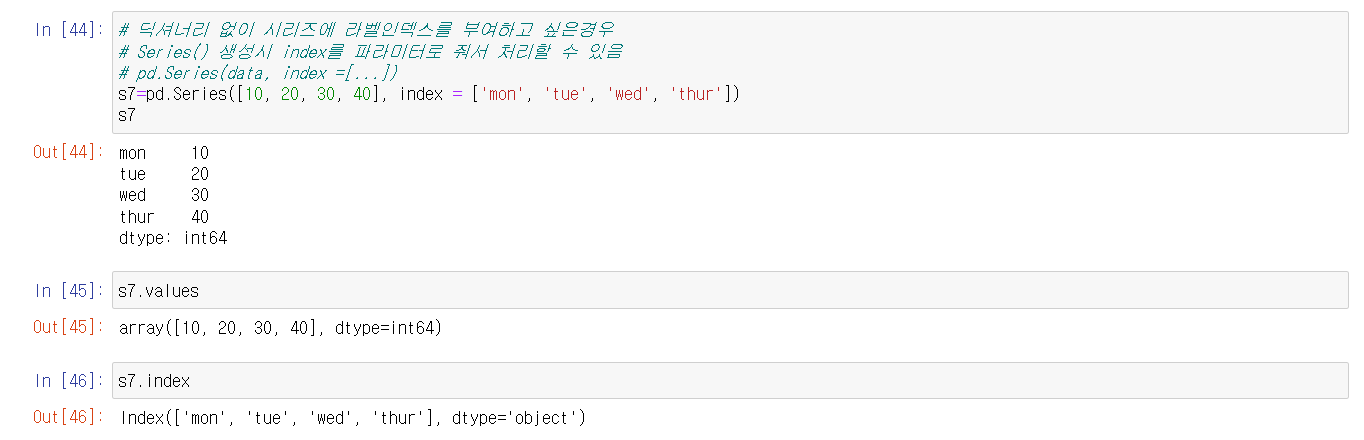
딕셔너리 없이 시리즈에 라벨 인덱스를 바꾼 상태로 만들고 싶을 경우
index를 파라미터로 줘서 처리할 수 있다.
values 와 index 확인 시 변한것을 확인할 수 있다.

Series 생성시 값에 딕셔너리를 넣으면
자동으로 index와 값으로 나뉘어 저장된다.


Numpy 인덱싱과 유사하게 하는것을 알 수 있다.

값을 변경하는것도 동일하며
다른점은 복수의 인덱싱을 할 경우 이중 리스트 형태로 조회해야한다.


* 슬라이싱 할 경우 범위는 마지막 위치 포함이다.

리스트 인덱싱과 같이 간격 또한 설정 가능하다.

객체에서 원하는 데이터만 보고 싶다면
조건 색인을 이용하면 된다.

양수와 음수가 섞인 Series를 생성해서 음수인 데이터만 보고 싶다면

위와 같이 몇번 인덱스의 몇은 음수일 경우 True 음수가 아닐 경우 False

만약 두 개 이상의 조건을 원한다면
if 조건문에서는 and 를 썼다면 Series에서는 & 기호로 이를 대체한다.

Numpy에서는 배열이 같지 않으면 산술연산이 불가능했다면
Series연산은 계산이 안된 값을 NaN으로 반환해 주어 계산이 가능하다.
* fill_value 인자를 통해 NaN값을 지정가능하다.


index 개수와 데이터 개수가 다른 두 Series를 생성해준다.

시리즈에 스칼라값을 곱해 계산이 가능하고
서로 다른 구조의 Series 끼리 더할경우 서로 다른 index의 데이터끼리 더한값은
값이 제대로 계산이 안되어 NaN값으로 나온다.
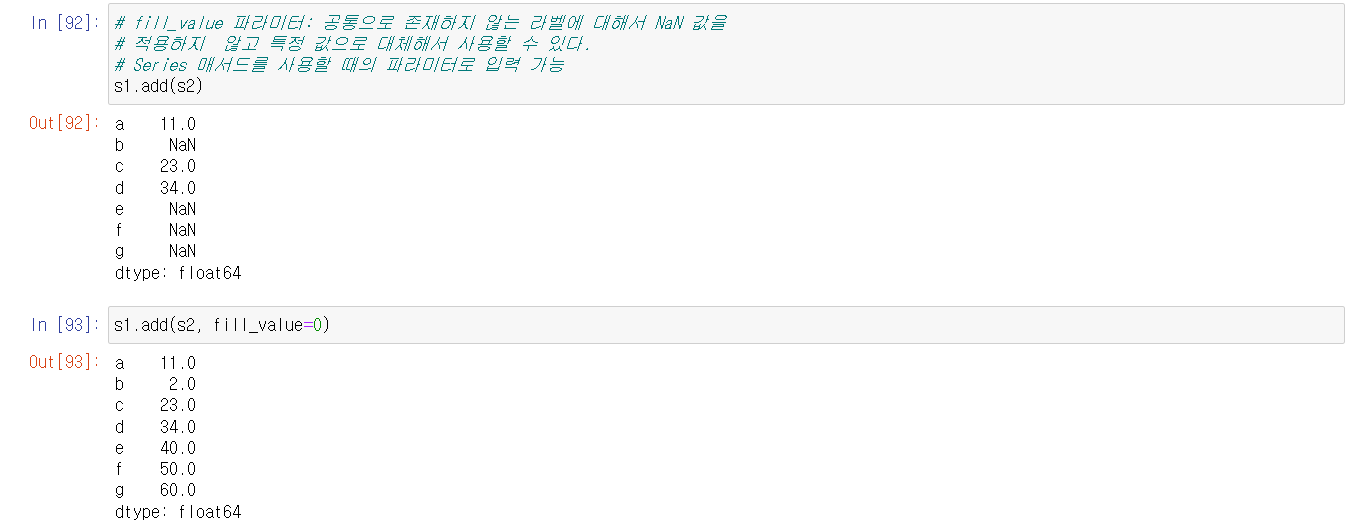
fill_value = 수 로 대체해서 연산 가능
'Hello python! > Python_DA' 카테고리의 다른 글
| 파이썬 데이터분석_데이터적재 (0) | 2022.10.29 |
|---|---|
| 파이썬 데이터분석_pandas_DataFrame (0) | 2022.10.29 |
| 파이썬 데이터분석_numpy변환(정렬, 참조, 복사)2 (0) | 2022.10.23 |
| 파이썬 데이터분석_numpy변환(정렬, 참조, 복사) (0) | 2022.10.22 |
| 파이썬 데이터분석_Numpy_연산 (0) | 2022.10.20 |



