20221021
13일차


여러개의 Series가 모인다면 어떻게 데이터를 처리해야 할까
정답은 DataFrame이다.
데이터 프레임은 여러가지의 데이터 타입으로 구성이 가능하다.
이렇게 모인 Series의 컬럼명이 컬럼 인덱스가 되고
그럼 자동으로 로우 인덱스가 생성된다.

주의할 점은 아이템의 길이가 같아야 한다.
ex) data1의 1 , 'a', 0 이 하나의 시리즈로 보기 때문에 다른 아이템들도 길이를 맞춰 줘야함.
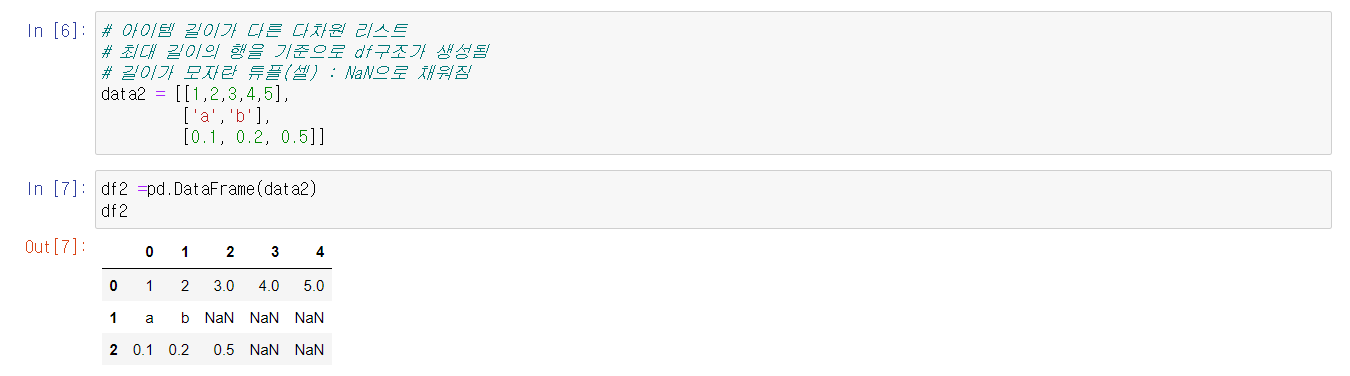
최대 길이의 행을 기준으로 df구조가 생성된다.
* Numpy 경우 배열과 다르게 아이템이 부족하면 생성이 안됬지만
DataFrame은 NaN값으로 출력됨.

딕셔너리 자료형을 데이터프레임 데이터로 사용할 경우key값 별로 매칭하기 때문에 value의 길이가 모두 동일해야 한다.

딕셔너리를 이용해 컬럼 순서를 변경해서 생성 할 수 있다.

DataFrame 속성에 대해 알아보자.
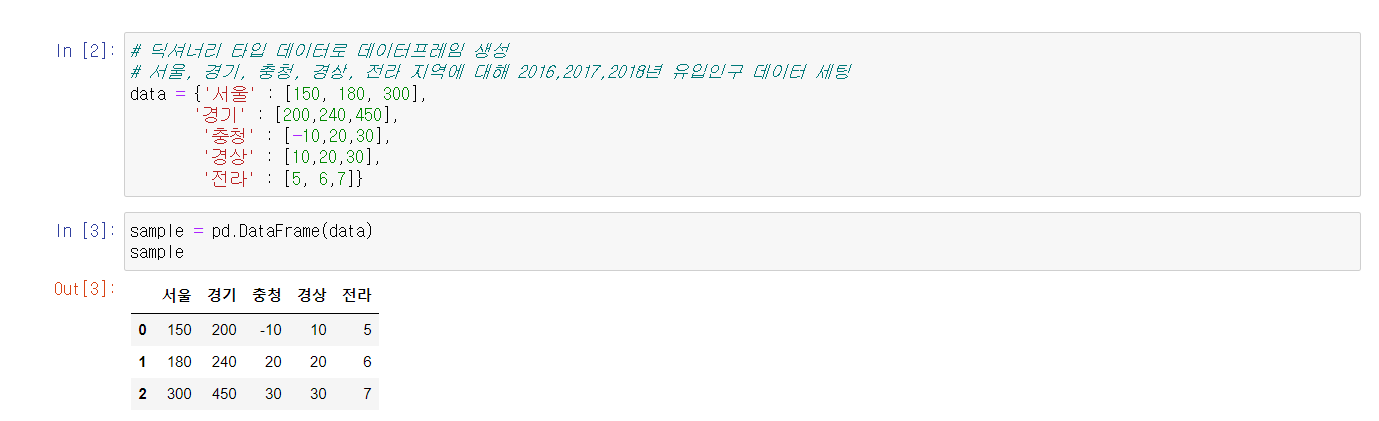
딕셔너리 형태로 data라는 변수에 저장 후 DataFrame화 해준다.

.index를 통해 row명을 바꿔 줄 수 있다.

* .index.name = "" 를 통해 row에 원하는 명칭을 달 수 있다.
* .columns.name = ""을 통해 columns에 원하는 명칭을 달 수 있다.
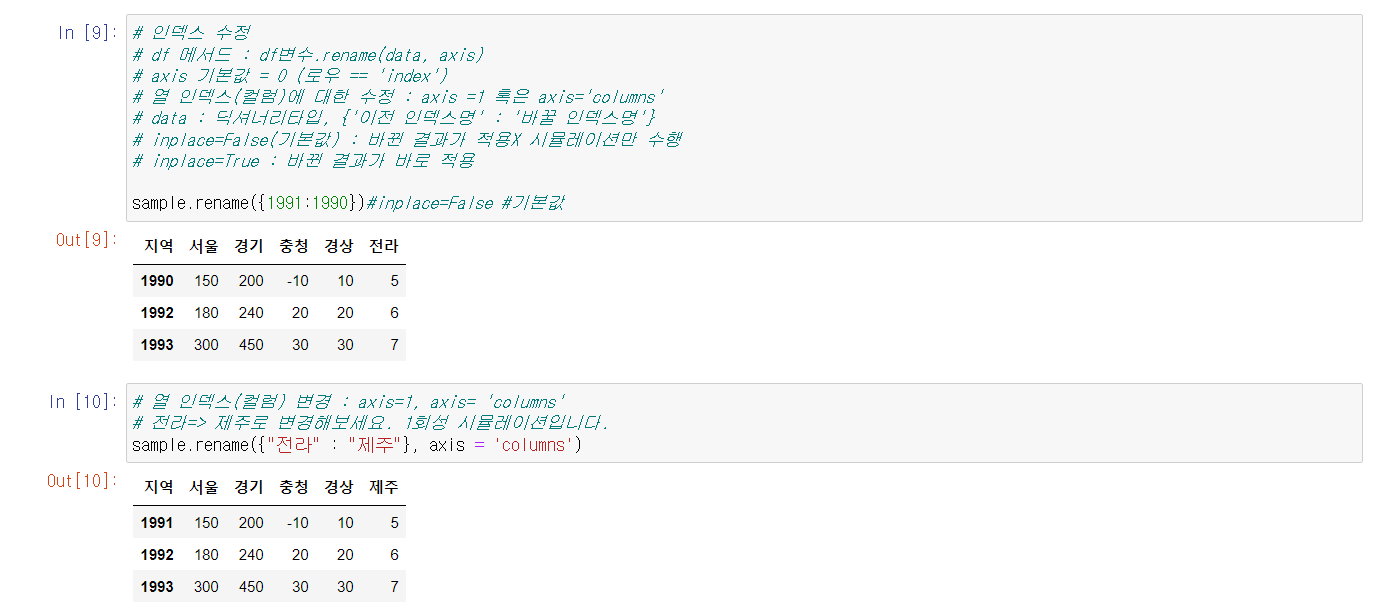
.rename을 통해 로우명을 바꿔줄 수 있다.
* axis = columns로 주면 컬럼명 변경 가능.

.axes는 로우 인덱스와 컬럼 인덱스를 보여준다.

.rest_index(drop=True)를 사용하면 row에 배정된 인덱스를 일괄 삭제한다.
* drop=True 를 주지 않으면 이전 인덱스가 컬럼으로 편입된다.
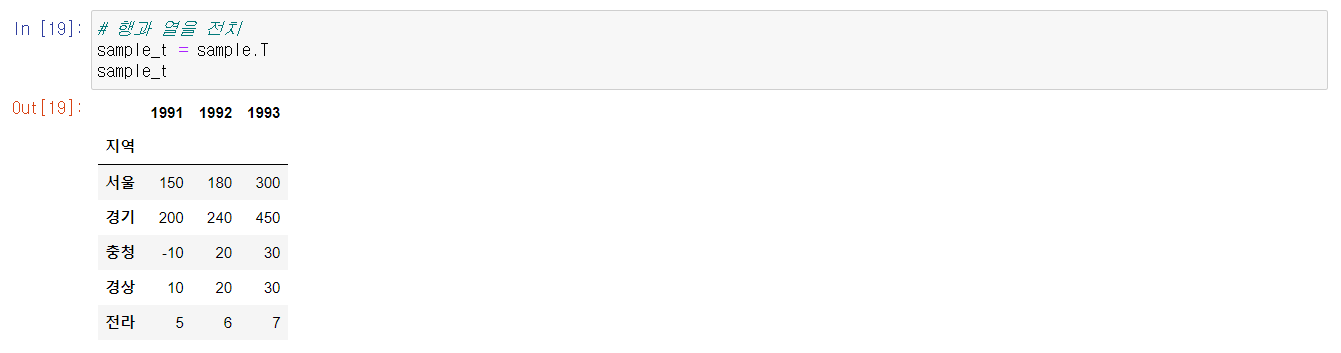
전치 행렬은 행과 열을 교환하여 얻는 행렬이다.

* 전치는 1회성으로 시뮬레이션만 보여준다.


1. 기본적으로 데이터프레임 변수 명에 [column명]을 넣으면 조회가 가능하다.
2. DF변수명 .'column명' 을 통해 조회 가능.
3. .get('column명')을 넣어서 조회 가능

로우 조회는
1. DF변수명.iloc[순서]를 통해 조회 가능하다.
2. DF변수명.loc[로우라벨명] 을 통해 조회 가능하다.
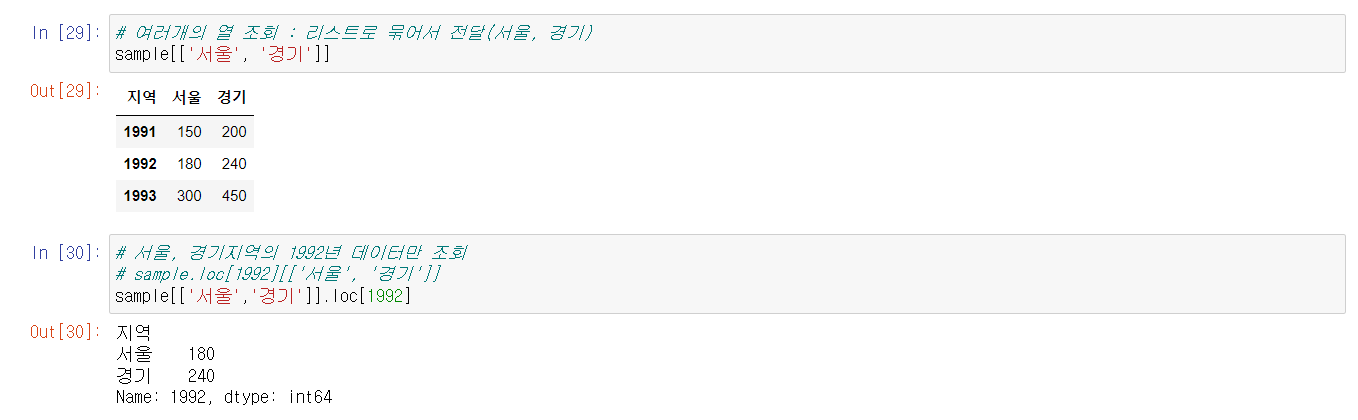
인덱싱을 통해 여러개의 Columns를 조회 할 수 있고
DF변수명[['Columns명']].loc[Row명] 을 통해 여러개의 컬럼안의 row값을 조회 할 수 있다.

반대로 여러개의 Row인덱스와 Column인덱스로 조회도 가능하다.
* 데이터프레임으로 시각화 하기위해 [[ ]]로 씌워준다.


슬라이싱 또한 구조가 비슷하다.

컬럼, 로우 추가에서는 배열을 추가하는 개념을 잊지말자.

위의 사진에서 숫자 1은 스칼라 값으로 본다.
따라서 같은 배열의 1,1,1이 제주컬럼의 아이템으로 추가 된다.

Numpy 배열로도 추가가 가능하다
* 대신 DataFrame의 구조에서 작게는 추가가 되지만 벗어나면 안됨.

같은 DF변수명의 Column명 끼리 연산이 가능하다.

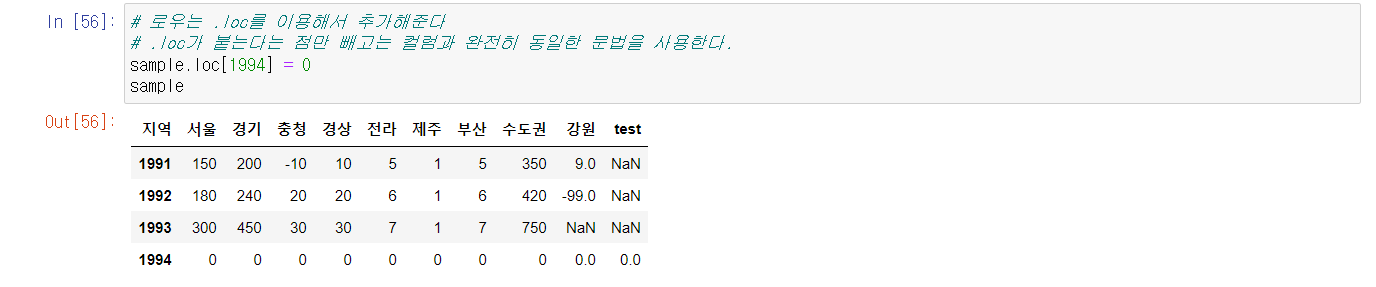
로우는 .loc가 붙는점만 빼고 컬럼과 동일한 문법을 사용한다.
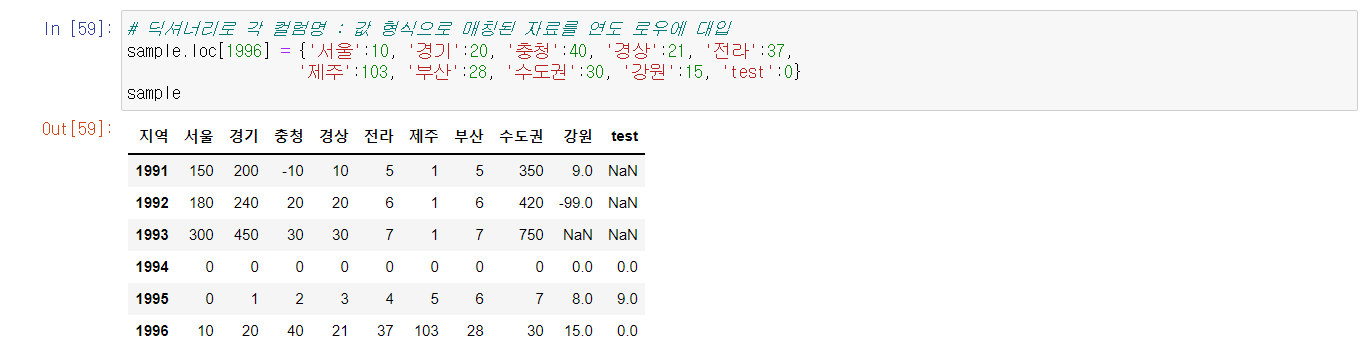
딕셔너리 형태로 대입이 가능하다.

로우,컬럼은 del과 .drop 로 삭제한다.
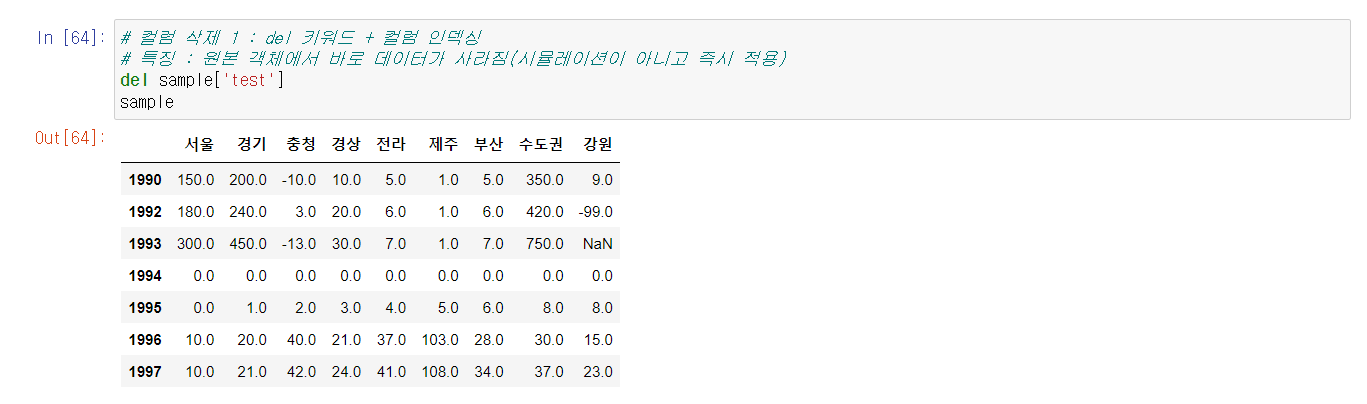
* del 함수는 원본에 바로 반영이 된다.

.drop 메서드는 그냥 쓰면 시뮬레이션만 보여준다.
하지만 뒤에 ,inplace=True를 붙이면 원본에 반영된다.

리스트로 묶어서 전달하면 다중 삭제도 가능하다.


두 개의 DataFrame을 만들어주고 산술 연산을 해보자.
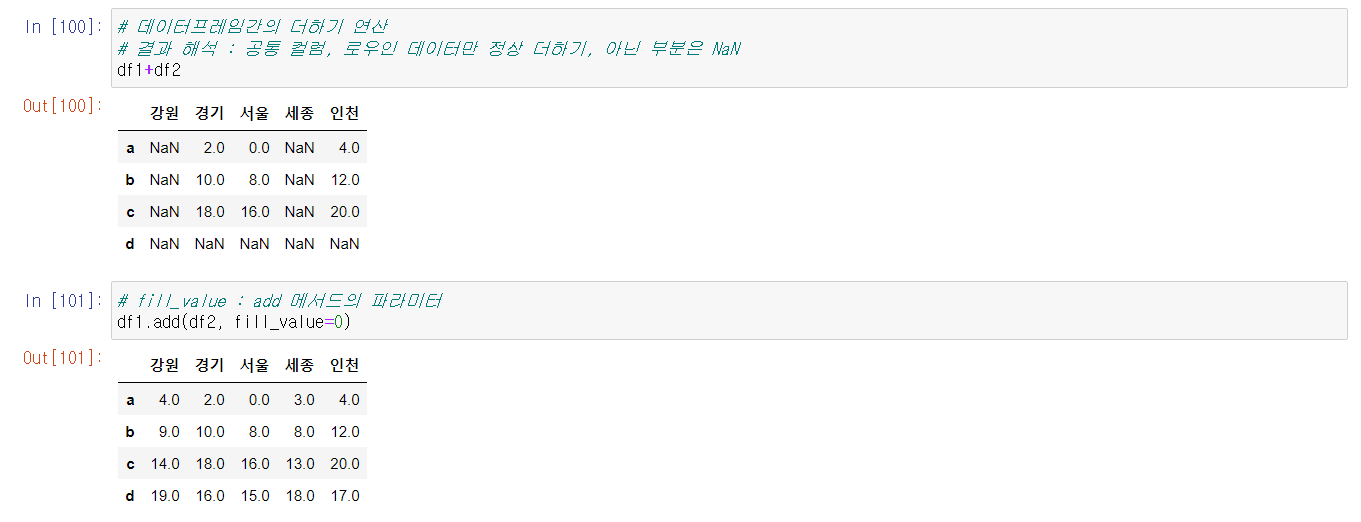
공동의 컬럼명끼리 연산이 된다.
* 다른 컬럼명 안의 데이터값은 NaN(Not a Number)처리된다.
* fill_value = 값 을 처리해주면 정해준 값으로 NaN가 채워져 계산된 결과를 보여준다.
- 도 마찬가지이다.

곱하기는 *와 .mul 메서드를 사용해 연산한다.
* 곱셈 나눗셈은 NaN를 처리하기 위해 fill_value 값을 1로 처리해주는게 편하다.
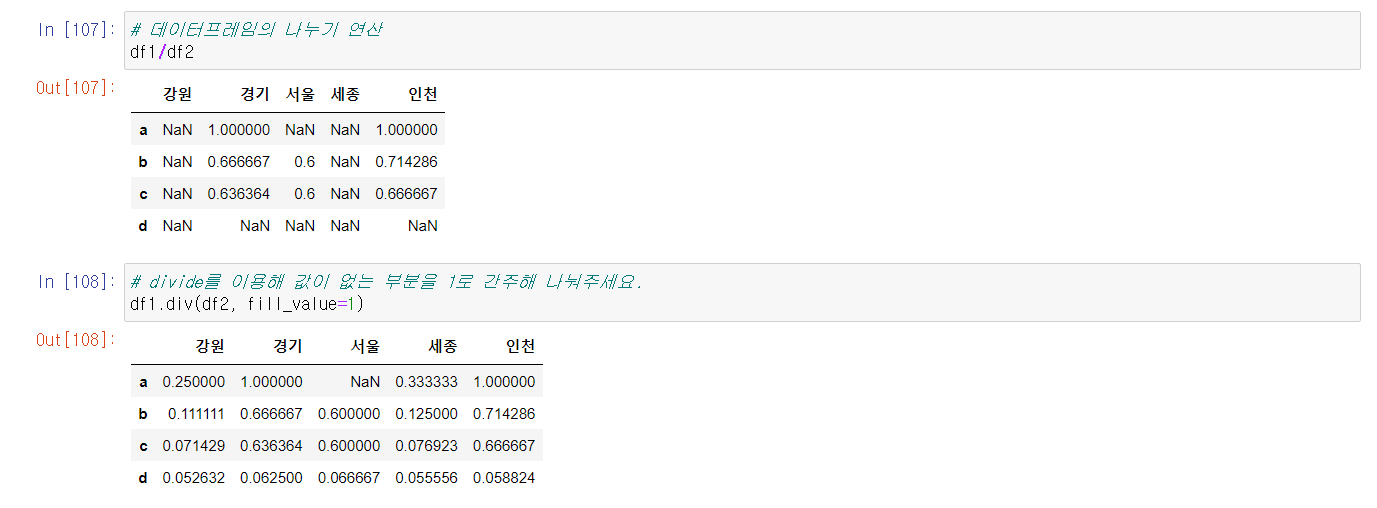
나눗셈은 / 와 .div를 이용해 연산한다.

DataFrame과 Series간의 연산은우선 구조가 같은지 확인컬럼명이 같은지 확인메서드를 사용해서 연산을 수행할때 방향(axis)을 어디로 둘지 정하기
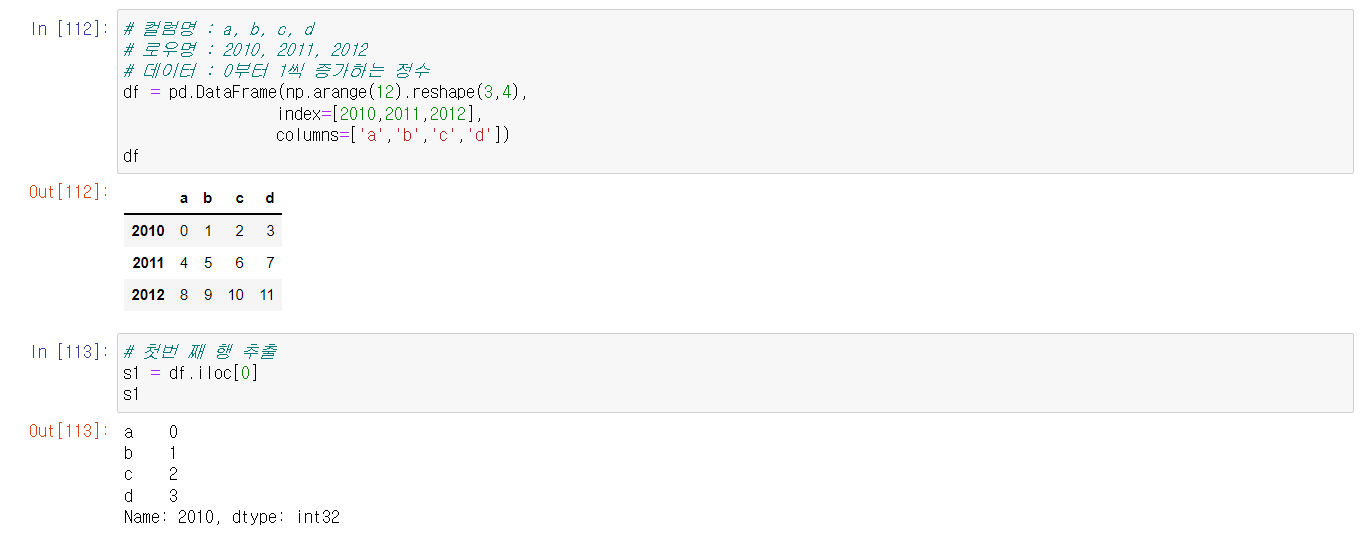
DataFrame과 Series 만들기.

이름이 일치할 경우 더하기
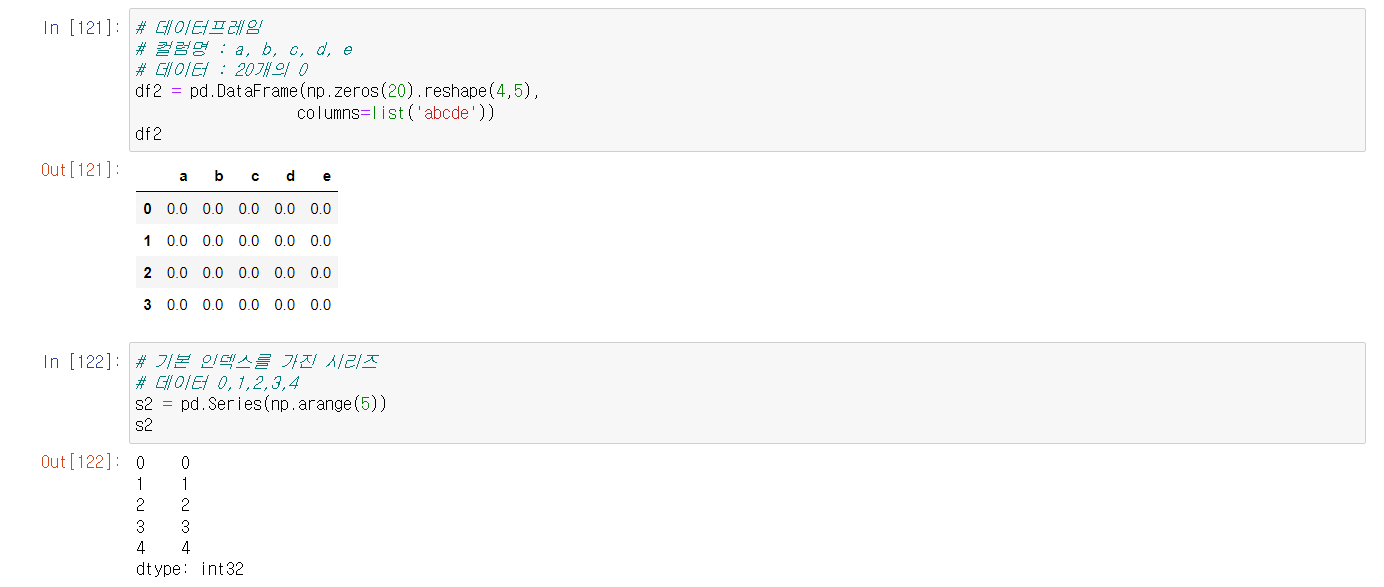
또 다른 형식의 DataFrame과 Series 생성
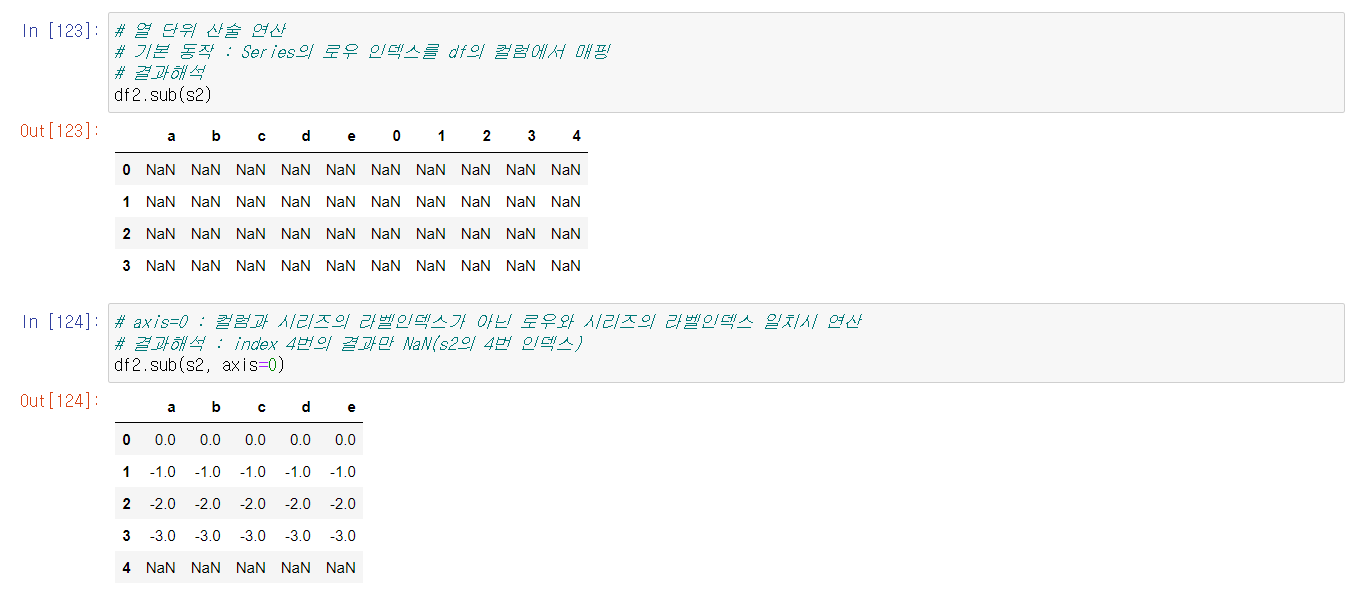
방향을 주지 않을 경우 NaN값으로 나오지만방향을 줄 경우 제대로 값이 나옴.
'Hello python! > Python_DA' 카테고리의 다른 글
| 파이썬 데이터분석_데이터 전처리 (0) | 2022.10.29 |
|---|---|
| 파이썬 데이터분석_데이터적재 (0) | 2022.10.29 |
| 파이썬 데이터분석_Pandas_Series 자료형 (0) | 2022.10.23 |
| 파이썬 데이터분석_numpy변환(정렬, 참조, 복사)2 (0) | 2022.10.23 |
| 파이썬 데이터분석_numpy변환(정렬, 참조, 복사) (0) | 2022.10.22 |



