20221006
3일차

지난 시간에 이어서
리스트 타입의 함수에 대해 복습해보자

리스트에 아이템을 추가하는 방법부터 보면

append() 라는 함수는 맨 뒤 하나의 인덱스에 아이템을 추가한다.
(여기서 하나의 인덱스라는것은 하나의 위치를 의미한다.)
조금 풀어서 설명하자면
인덱스는 각각 순서와 위치가 존재한다.
위의 a라는 리스트는 1, 2, 3 이라는 아이템을 가지고 있으며 각각
0번째, 1번째, 2번째에 위치한다.
그래서 예를 들어 append()라는 함수를 써서 4라는 아이템을 추가할 경우
a 리스트의 3번째에 들어가는 것이다.

추가적으로 한개의 아이템이 아닌 두개의 아이템을 묶어서 넣고싶을 경우
[]로 묶어서 삽입한다.
* 위치는 4번이 된다.

extend() 함수는 추가 아이템의 대상이 리스트인 함수이다.
append() 와 차이점은 1자리만 추가하는것이 아닌 추가하는 리스트의 아이템이 순서대로
자리를 차지한다.
*하나의 인덱스만 연장해도 리스트로 추가해야 한다.

insert() 함수는 대상리스트에 몇 번째에 어떤 아이템을 넣고 싶을때 사용한다.
append()함수처럼 한 자리에 아이템을 추가하는것이니 유의하자.

in 키워드는 리스트 내에 내가 찾고 싶은 아이템이 있는지 확인하고 싶을때 사용한다.
그래서 결과는 True or False로 답한다.
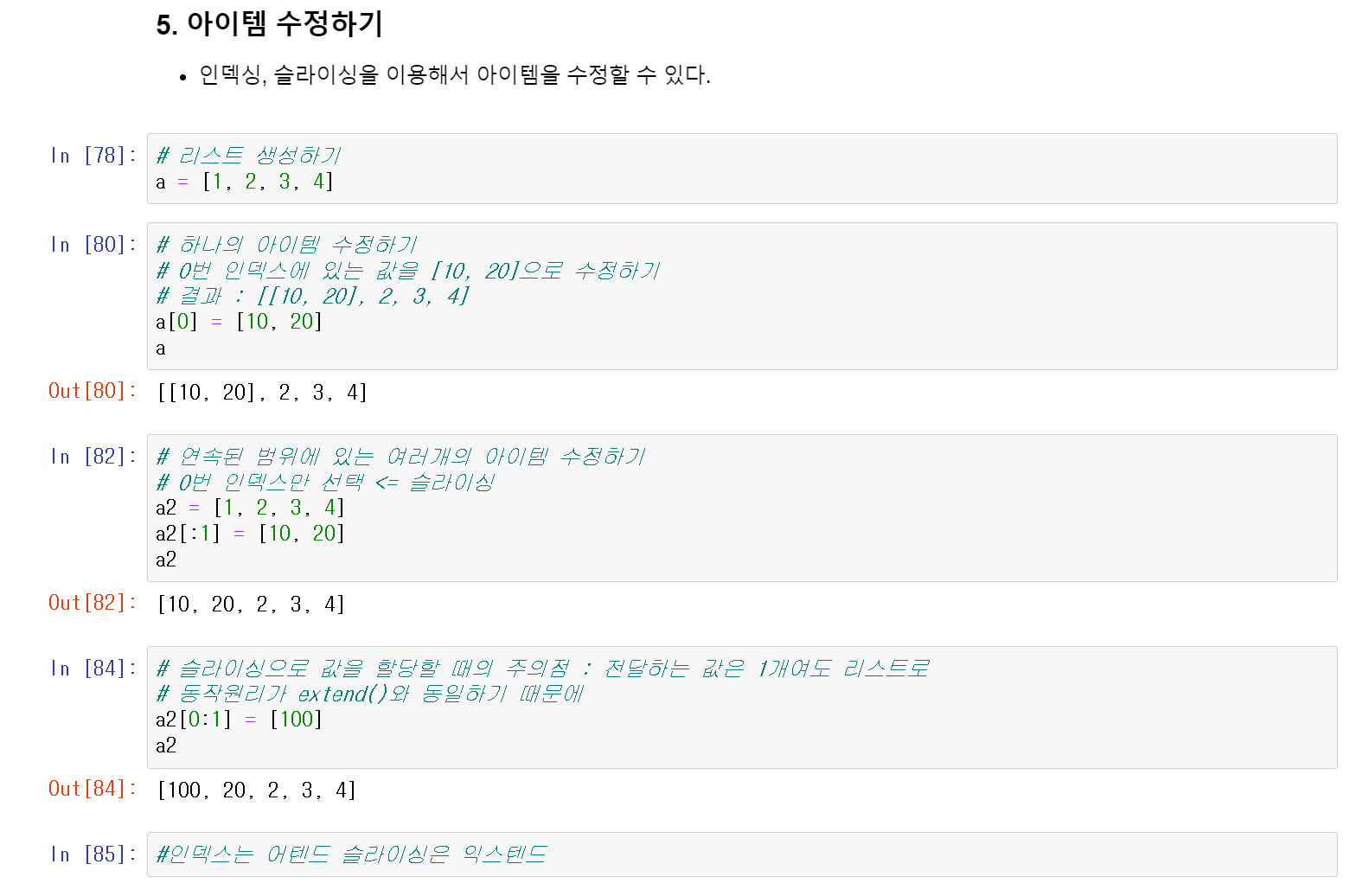
인덱싱과 슬라이싱을 통해 원하는 위치의 아이템을 수정할 수 있다.
인덱스는 attend()와 유사하고
슬라이싱은 extend()와 유사하다.

추가는 방법이 있다면 삭제하는 방법도 있는 법.

0번째 부터 1번째까지 null을 이용해 삭제하는 방법이 있고

del을 이용해 어떤 리스트의 몇 번째를 삭제하는 방법이 있다.
만약 인덱싱 없이 del을 쓰면 모든것을 삭제한다.

del은 슬라이싱으로도 삭제가 가능하다.
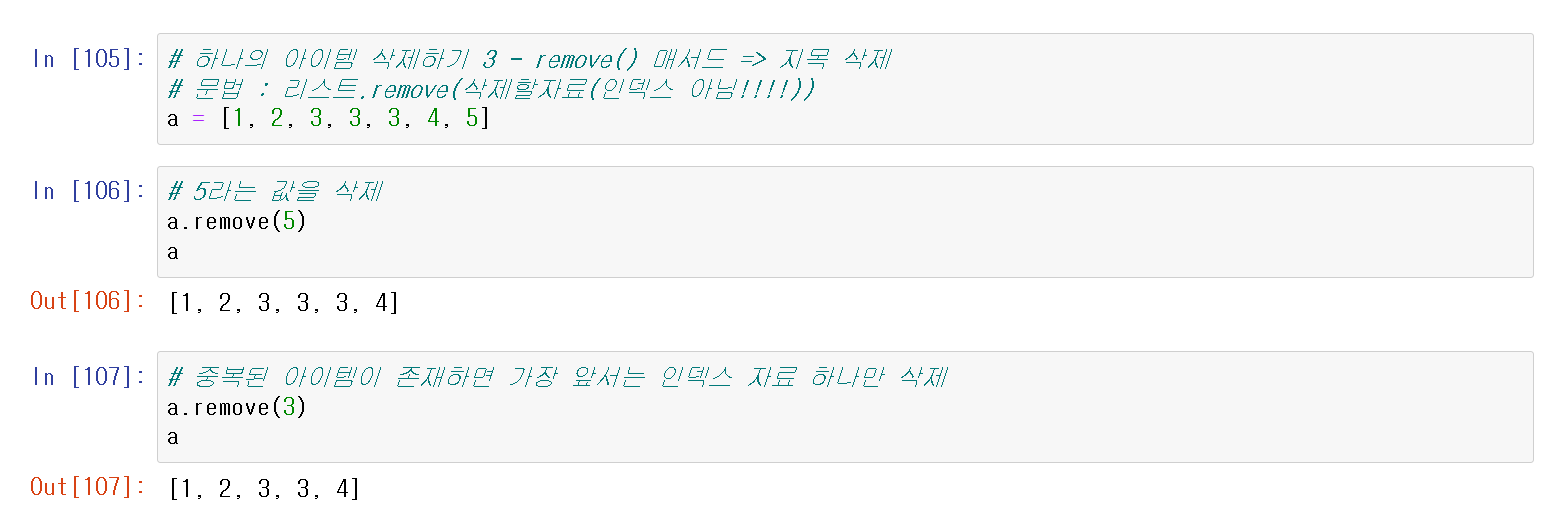
remove()는 원하는 아이템을 지정하여 삭제가 가능하다.
또한 중복된 아이템이 있는 경우 중복된 아이템 중 맨 앞에 아이템을 삭제한다.
* 인덱스가 아닌것을 유의하자.
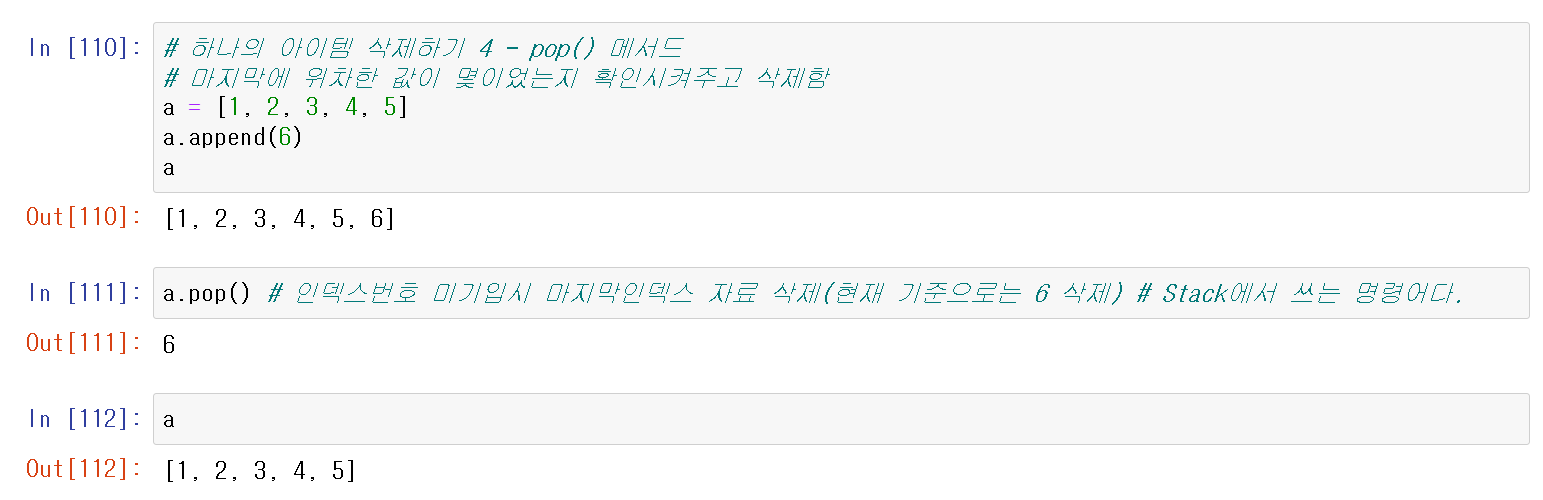
pop() 메서드는 마지막에 위치한 값이 몇이었는지 확인시켜주고 삭제한다.
위의 사진과 같이 111번 결과를 보면 6이 마지막 아이템이라고 확인을 시켜준다.

만약 삭제하려는 인덱스 번호를 지정하면 지정위치를 삭제한다.

Stack과 Queue의 차이를 명확하게 인지하자.
선입선출 vs 후입선출.

리스트의 아이템 정렬하기.

만약 리스트 안의 아이템이 뒤죽박죽 섞여 있다면 어떻게 해야할까?
리스트.sort()를 쓰면 된다.
()안에는 reverse를 참(True)으로 할것이냐 거짓(False)으로 할것이냐 선택해 주면 된다.
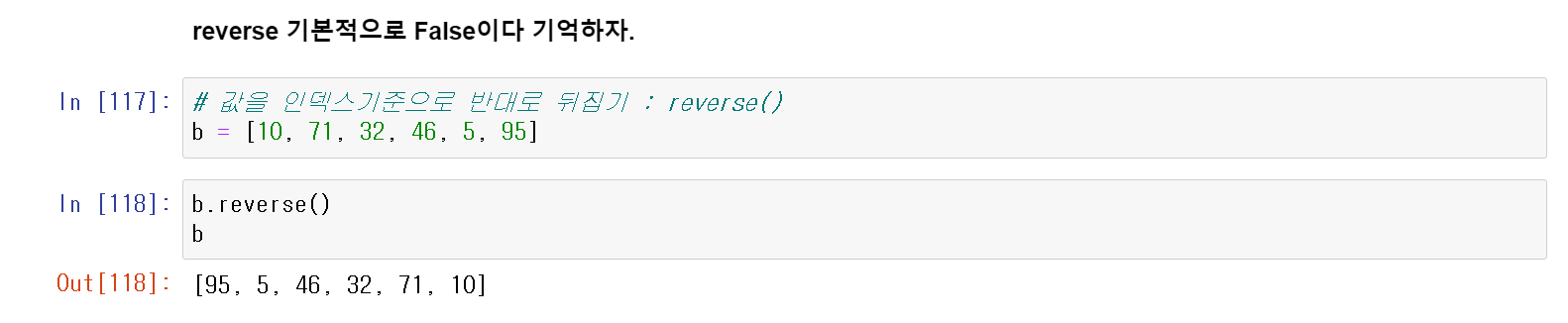
차순에 상관 없이 데이터를 뒤집고 싶다면
reverse()를 사용하면 된다.
* 기본적으로 reverse()는 False이다.
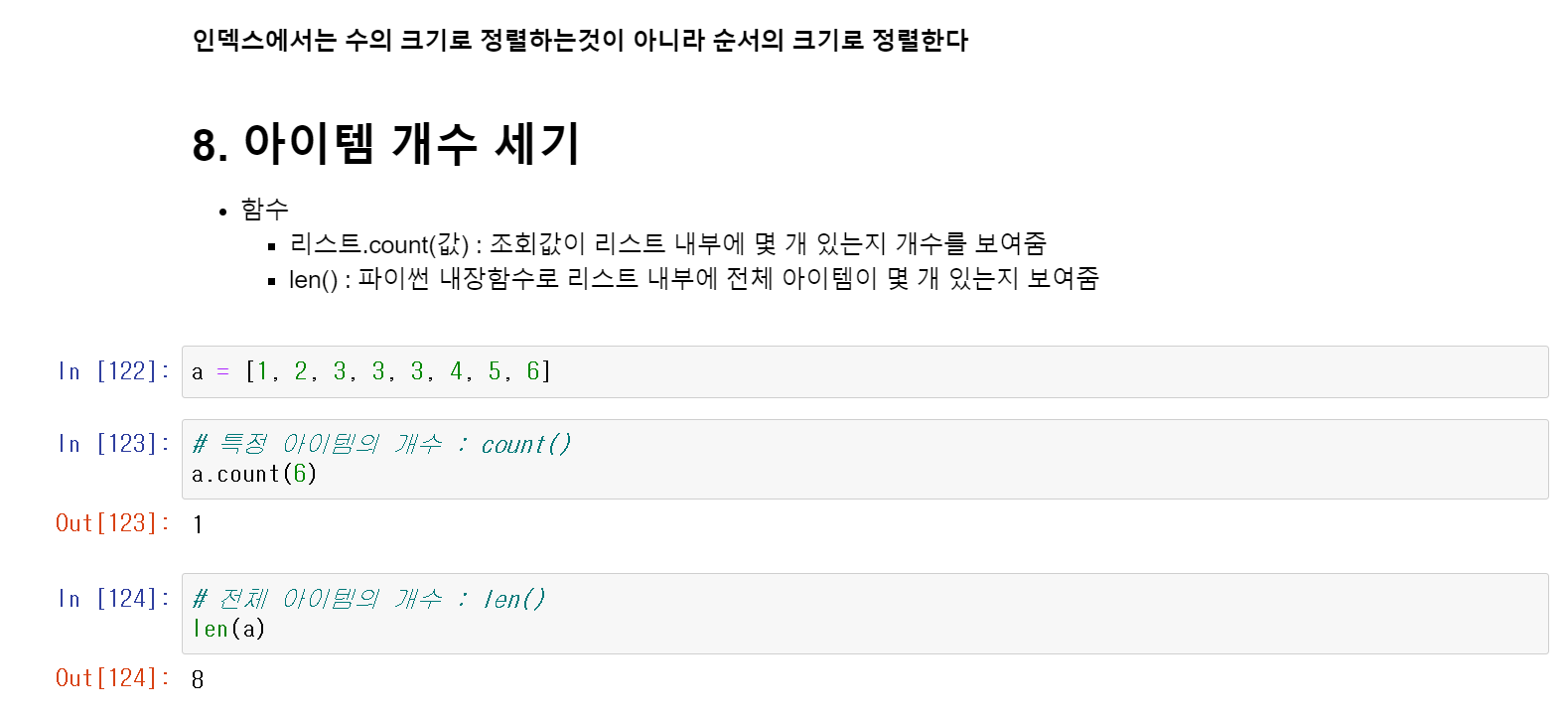
리스트 안에 육안으로 확인할 수 있는 개수만 들어있을 가능성은 적다.
수천 수만개의 아이템의 갯수를 파악하고 싶을때 또한 특정 아이템은 몇개 있는지 확인하고 싶을때
count()메서드를 쓴다.
만약 위의 사진에서 3이라는 아이템은 몇개 있는지 확인하고 싶다면
a.count(3)
3
이라고 결과가 나올 것이다.
전체 아이템은 len(리스트명)을 사용하면 된다.

간편하게 사진으로보면 메모리는
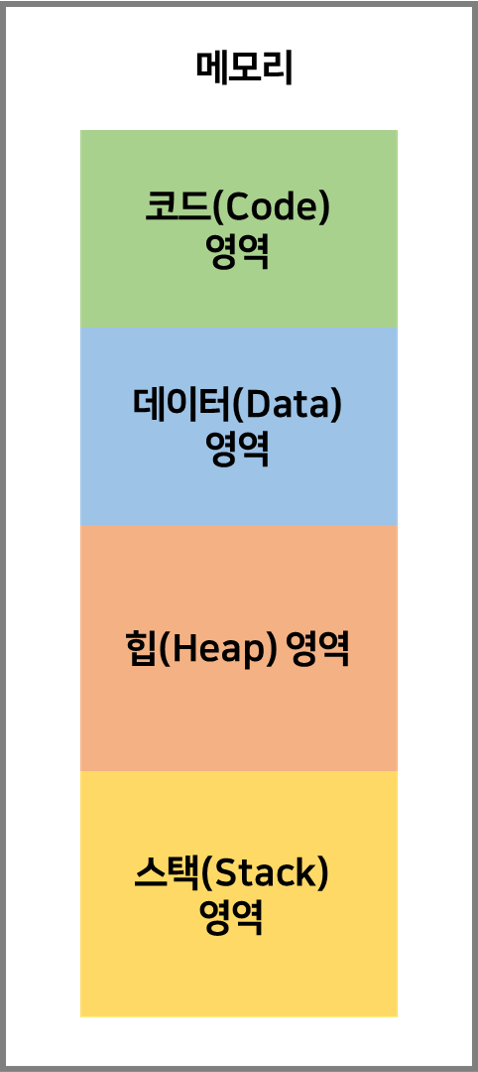
코드(code)영역, 데이터(Data)영역, 힙(Heap)영역, 스택(Stack)영역으로 나뉘며,
각각의 자세한 내용은 따로 정리하기로 하고 스택과 힙만 봐보자.
이 개념을 필히 이해하고 갈 필요가 있는데, 이해한것을 떠올려보자면
기본적으로 스택은 용량이 작고 힙은 용량이 크다.
그 결과 스캔의 빠르기가 다르고 저장 공간이 다르다.
예를 들어 리스트 a = [1, 2, 3, 4, 5]라고 가정하면
a는 스택에서 주소를 갖고 [1, 2, 3, 4, 5]는 힙에 저장되어 주소를 갖는다.
[1, 2, 3, 4, 5]의 아이템 [1], [2], [3], [4], [5]는 힙에서 N번지로 저장이 된다.
그래서 우리는 a를 실행하면 [1, 2, 3, 4, 5]라는 결과가 나오는 간편함을 볼 수 있다.
요정도로 이해했다.
(더 공부할 필요성을 느낀다.)
아직 명칭과 설명이 미흡하지만 따로 공부해서 다시 올려야겠다.


우선 기본적으로 = 을 이용하여 복사가 가능핟.

id(변수)를 통해 주소를 확인해 보면 같은 주소인걸 확인할 수 있다.
* a = [1, 2, 3, 4, 5] 일때 a는 스택에 [1, 2, 3, 4, 5]는 힙에 주소를 갖는다.
하지만 a = b 이므로 b 또한 같은 힙주소에서 불러오게 되는 것이다.
[1, 2, 3, 4, 5] ⇢ a = b
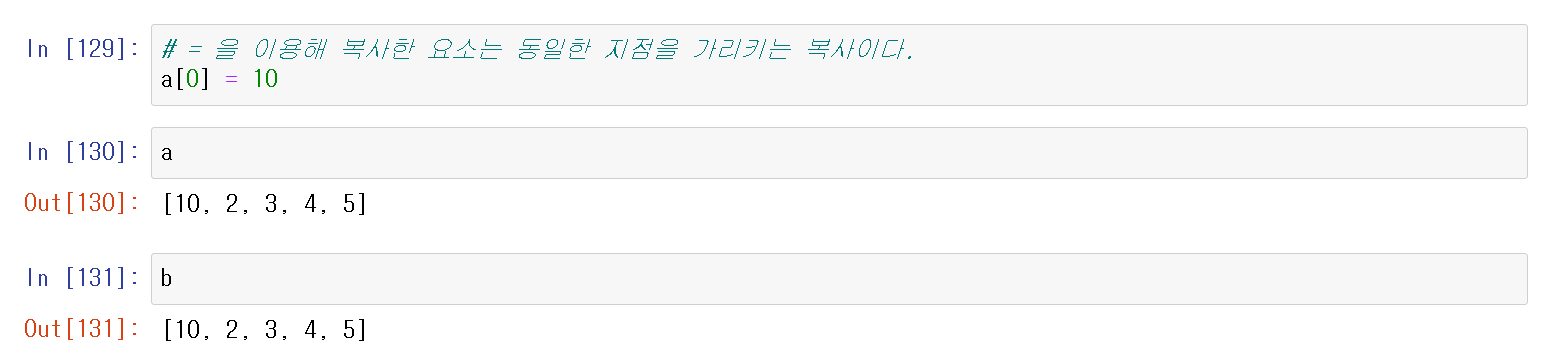
순서 또한 같은 순서이다.
* a의 0번째 위치 1을 10으로 변경하면
b의 0번째 위치 1 또한 자동으로 10으로 변경됨.

copy() 매서드는 a라는 리스트를 복사하는 것이다.
* 같다라는 의미와 복사라는 의미는 다르다.
그래서 새롭게 복사된 c는 힙에 내용물은 같지만 주소는 다른 리스트가 된다.
고로 a를 변경해도 b는 변경되지만 복사한 c는 변경되지 않는다.
🔥
얕은 복사 : 스택 단위의 복사 같은 힙 주소를 가짐
깊은 복사 : 힙 단위의 복사 다른 힙 주소를 가짐

list()로 복사시 깊은 복사로 힙의 주소가 다르다.
슬라이싱 또한 깊은 복사이다.
하지만 아이템은 육안으로 같게 보인다.
'Hello python! > python_Basic' 카테고리의 다른 글
| 파이썬 시작 (자료형_딕셔너리) (0) | 2022.10.10 |
|---|---|
| 파이썬 시작 (자료형_리스트,튜플3) (0) | 2022.10.10 |
| 파이썬 시작 (자료형_리스트,튜플) (0) | 2022.10.05 |
| 파이썬 시작 (데이터타입_문자) (2) | 2022.10.05 |
| 파이썬 시작 (데이터타입_숫자) (2) | 2022.10.05 |



