23.01.01

자연어 처리 (Natural Language Processing)
자연어 처리란,
컴퓨터가 인간의 언어를 이해, 생성, 조작할 수 있도록 해주는 인공지능(AI)의 한 분야
자연어 텍스트 또는 음성으로 데이터를 상호 연결하는 것으로
'언어 입력(language in)'이라고도 한다.
Oracle Digital Assistant(ODA)나 Siri, Cortana, Alexa와 같은 가상 도우미의 핵심 기술
웹 검색, 스팸 메일 필터링, 텍스트 또는 음성 자동 번역, 문서 요약, 감정 분석, 문법/철자 검사 등이 있다.
쉽게 설명하면 자연어 처리란 인간이 사용하는 언어를 컴퓨터가 인식하게 학습 하는것.
🔥 NLP의 영역 🔥
💡 자연어 이해(Natural Language Understanding)
컴퓨터를 사용하여 인간의 언어를 이해하는 것
과거에는 사용자가 원하는 자연어를 이해하는데 수 많은 데이터가 필요했지만,
자연어 이해를 사용한 모델을 통해
과거의 단점을 보완하였다.
Human : "날씨 알려줘."
Computer : (날씨 알려줘 의미 확인 # 자연어 이해) ▶ (수 많은 날씨관련 데이터 검색) ▶ (H가 원하는 결과물 전달)
💡 자연어 생성(Natural Language Generation) = '언어 출력(language out)'
컴퓨터를 사용하여 인간의 언어를 생성하는 것
= 컴퓨터의 학습 결과를 사람의 언어를 표현하는 기술
대표적인 예시로 챗봇(Chat Bot)이 있다.
NLU과정에서 한 단계 진화하여이해 + 생성의 기술을 구현하는것.

🔥 NLP 머신러닝 기술 🔥
NLP는 현재 머신러닝에 크게 의존한다.
때문에 이를 학습시키기 위해서
다양한 데이터 세트의 예시문을 활용해 예측을 수행한다.
그 결과 문장이 지닌 감정을 예측하는 모델을 만들 수 있으며
= 문서 분류 모델 (Document Classification Model)
문서의 개체(entity)를 인식하고 분류하는 모델이 만들어졌고
= 시퀀스 레이블링 모델(Sequence Labeling Model)
문서를 입력값으로 사용하지만 문장이나
다른 시퀀스를 출력값으로 생성하는 모델도 생성되었다.
= 시퀀스 투 시퀀스(Sequence-to-sequence) 모델
# 번역기
🔥 NLP 전처리 기술 🔥
인간의 언어란 약속이 존재한다.
같은 모양의 글자지만 각각의 순서와 위치에 따라
의미가 달라지며 문법또한 각 언어마다 다르다.
이를 컴퓨터가 정확히 인지하고 학습하기 위해
자연어 또한 전처리 기술이 필요하다.
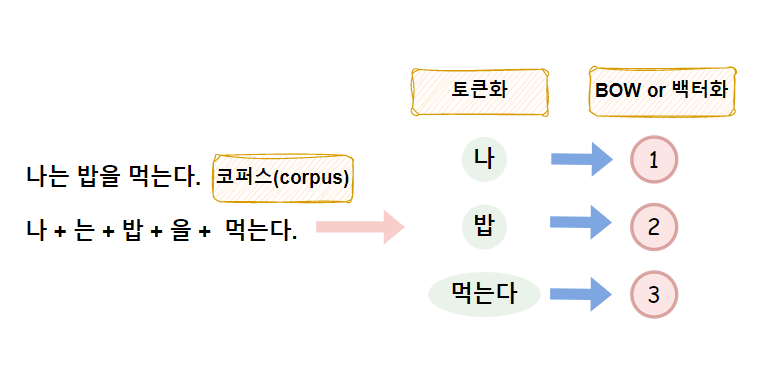
1. 토큰화 (Tokenization)
✔ 토큰화는 원시 텍스트 # 코퍼스 (corpus)를 단어 또는 단어 조각을 토큰 시퀀스로 분할하는 것을 말한다.
쉽게 설명하면, 내가 지키고 싶은 의미를 가진 단어를
토큰으로 만들어주는 것이다.
= 최소 의미 단위로 치환된다.
✔ 코퍼스 (corpus)
= 자연언어 연구를 위해 특정한 목적을 가지고 언어의 표본을 추출한 집합.
2. 단어 주머니 모델(Bag-of-words models, BOW)
빈도수 기반의 단어 표현 방법으로 단어들의 가방이라는 의미
보통 각 단어에 고유한 인덱스를 부여하고
각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 백터를 만든다.
3. 불용어 (Stop word) 제거
✔ 불용어
= 분석 목적상 큰 도움이 되지 않는 단어들
유의미한 토큰들만 선별하기 위해서
의미없는 토큰을 제거하는 과정
조사와 접미사 같은 경우 자주 등장하지만
학습하는데 있어서는 기여도가 적음
4. 어간 추출(Stemming) 및 표제어 추출(Lemmatization)
= 정규화 기법 중 코퍼스에 있는 단어의 개수를 줄일 수 있는 기법
시각적으로는 다른 단어이지만,
하나의 단어로 일반화 시킬 수 있다면 일반화 시켜
가지고 있는 코퍼스로부터 복잡성을 줄이기 위함
💡 어간 추출(Stemming)
✔ 어간(Steam)이란 단어의 의미를 담고 있는 단어의 핵심 부분을 뜻한다.
형태론 및 정보 검색 분야에서 어형이 변형된 단어로부터
접사 등을 제거하고 그 단어의 어간을 분리해 내는 것을 의미한다.
✔ 접사 (Affix)
= 단어에 추가적인 의미를 주는 부분.

💡 표제어 추출(Lemmatization)
✔ 표제어(Lemma)란 기본 사전형 단어를 의미한다.
표제어 추출이란 단어들로부터 표제어를 찾아가는 과정.
단어의 형태가 다르더라도 뿌리 단어를 찾아가서 단어의 수를 줄일 수 있는지 판단.
단어의 형태학적 파싱을 먼저 진행하는것이 가장 섬세하다.
✔ 형태소(Morpheme)
= 의미를 가진 가장 작은 단위
어간(Stem)과 접사(Affix)가 존재한다.

✔ 형태학(Morphology)
= 형태소로부터 단어들을 만들어가는 학문


'Developer Diary' 카테고리의 다른 글
| Toy Project 5일차 (0) | 2023.01.03 |
|---|---|
| Toy Project 4일차 (0) | 2023.01.03 |
| 확률 변수 & 분포 (0) | 2022.12.26 |
| 시계열 분석 (0) | 2022.12.25 |
| Toy Project 3일차 (0) | 2022.12.23 |



