20221122
35일차

오늘 해볼 실습은 U-Net 신경을 이용한
사진의 피사체 특징 추출(분할)이다.
image의 annotation만 있는 사진과
image가 있는 사진들을 다운받았다.

U-Net 설명에 앞서
왜? 라는 질문으로 글을 시작하려 한다.
지금까지 우리는 원하는 이미지를 구별하는 과정을 실습해보았다.
이미지를 컴퓨터에게 학습 시키는 러닝의 궁극적인 목표는 결과의 실사화가 아닐까란 생각을 한다.
이미지의 해상도가 점점 발전해가고 있는 시대에서
우리는 보다 정확한 데이터를 가져오기위해
조금 더 정확한, 조금 더 세밀하게, 조금 더 원하는 범위라는 욕심이 생겼을 것이다.
예를 들어 핏줄 하나하나, 털 한가닥 한가닥, 표면의 재질, 멀리 찍혀있는 꽃 하나하나 같은
좀 더 실용적이고, 가치가 있는 결과물을 원한다는 의미이다.
이를 위한 스탭중 생겨난 모델이 U-Net이다.
💡U-Net ?
U-Net은 역시 기존의 CNN모델의 단점을 극복하고자하는 이유도 가지고 있다.
CNN은 kernel을 이용해 이미지의 특징을 간추려내고 결과를 내기 때문에
특징을 포함한 영역의 데이터를 학습해왔고, Detection분야에서 한계를 맞는다.
Ⅰ. U-Net은 이러한 한계를 이미지 세그멘테이션(image segmentation)을 활용해
한계를 돌파한다.
⭐ 이미지 세그멘테이션(image segmentation)
디지털 이미지를 이미지 영역 또는 이미지 객체라고도 하는 여러 세그먼트로 분할하는 프로세스.
이미지 분할은 동일한 선, 곡선등의 이미지에서
같은 레이블을 가진 픽셀이 특정 특성을 공유하도록
이미지의 모든 픽셀에 레이블을 할당하는 프로세스.
이미지 분할은 일반적으로 객체와 경계를 찾는데 사용.
쉽게 설명하면 디지털 이미지의 객체와 경계를 찾아
모든 픽셀에 정보를 공유하고 러닝모델에 학습시켜
비슷한 이미지가 오면
경계와 객체를 구분해주는 역할을 하는데 도움을 주는 프로세스이다.
Ⅱ. U-Net은 오토인코더(autoencoder)와 같은 인코더-디코더(encoder-decoder) 기반 모델에 속한다.
💡 인코더-디코더(encoder-decoder)?
- 인코더(encoder) : 인지 네트워크(recognition network)라고도 하며, 입력을 내부 표현으로 변환한다.
- 디코더(decoder) : 생성 네트워크(generative nework)라고도 하며, 내부 표현을 출력으로 변환한다.
# ResNet에서 인코더에 해당하는 부분은 BasicBlock의 순전파, 디코더는 ResNet 순전파에 해당한다.
즉, U-Net은 인코더로 이미지의 특징을 가중치를 잘줘서 뽑고
디코더로 이미지를 잘 내보내는 것이다.
이때 U-Net모델은 디코더과정중 Pooling Layer를 사용하는것이 아니라
Up-Sampling(Up-Conv)을 사용한다.
💡Up-Sampling
Pooling 레이어를 거치면서 축소된 피처맵을 원본 이미지의 크기로 되돌리기 위해서 사용하는 방식
# Conv와 Pooling을 통과시키면서 원본 이미지를 압축해나가는 과정을 Downsampling
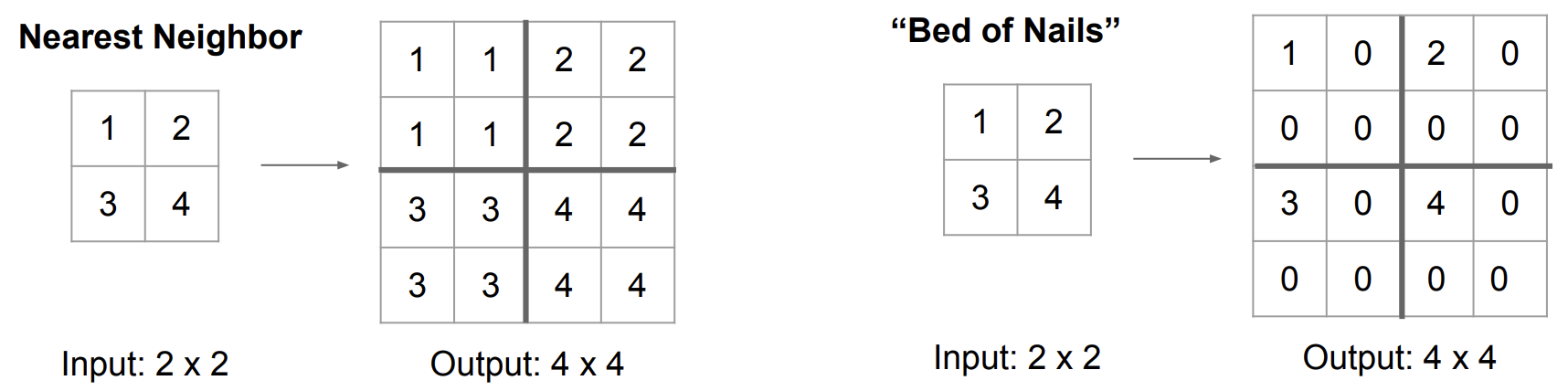
Nearest Neighbor / Bed of Nails
▶ 주변 값을 참조하여 채운다.
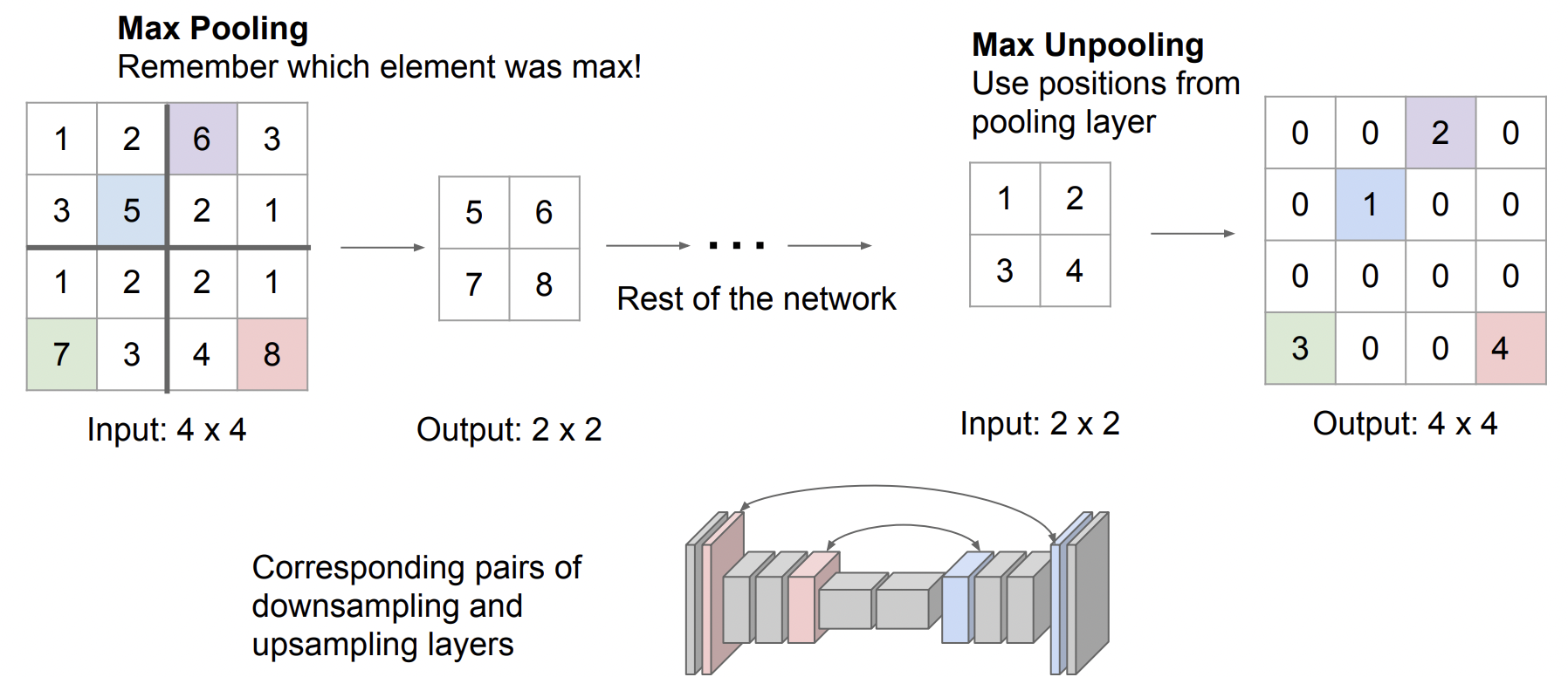
Max Unpooling
▶ Max pooling 최대값 위치를 기억하여 다시 그자리에 채운다.
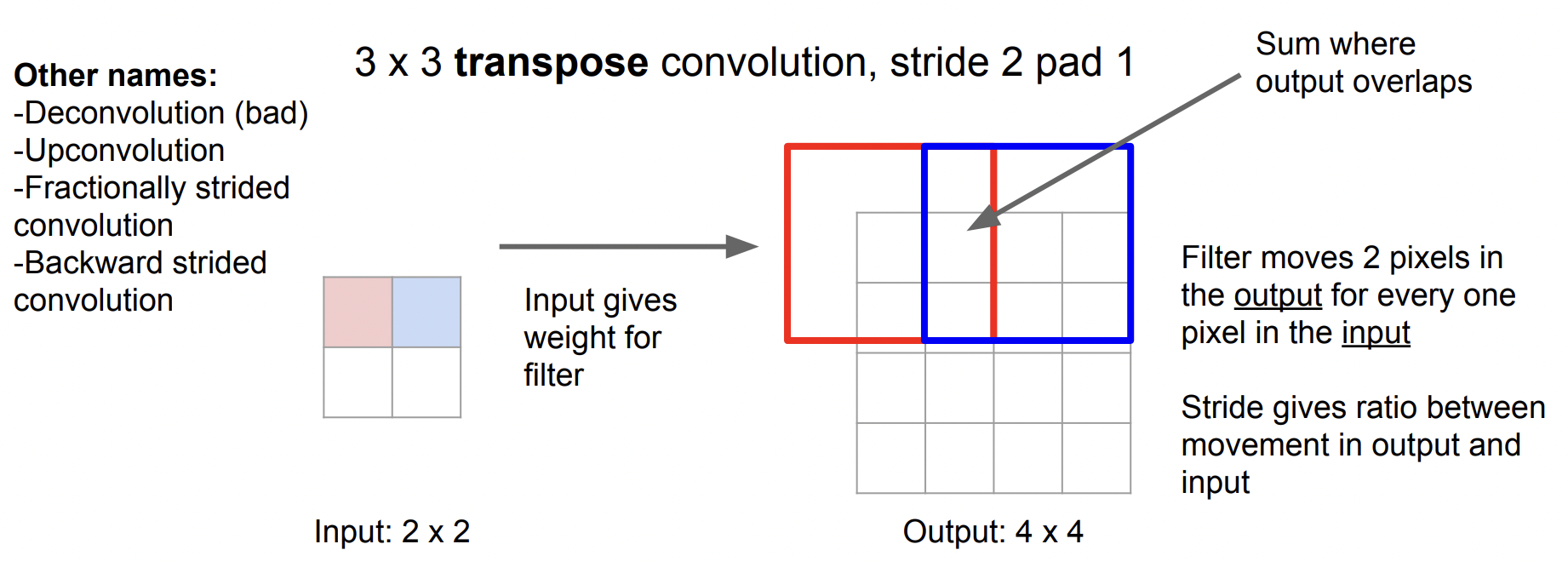
Transpose Convolution
▶ 고정된 학습값을 입력 이미지에 stride 수만큼 슬라이딩 하면서
합성곱 연산 결과값으로 채움
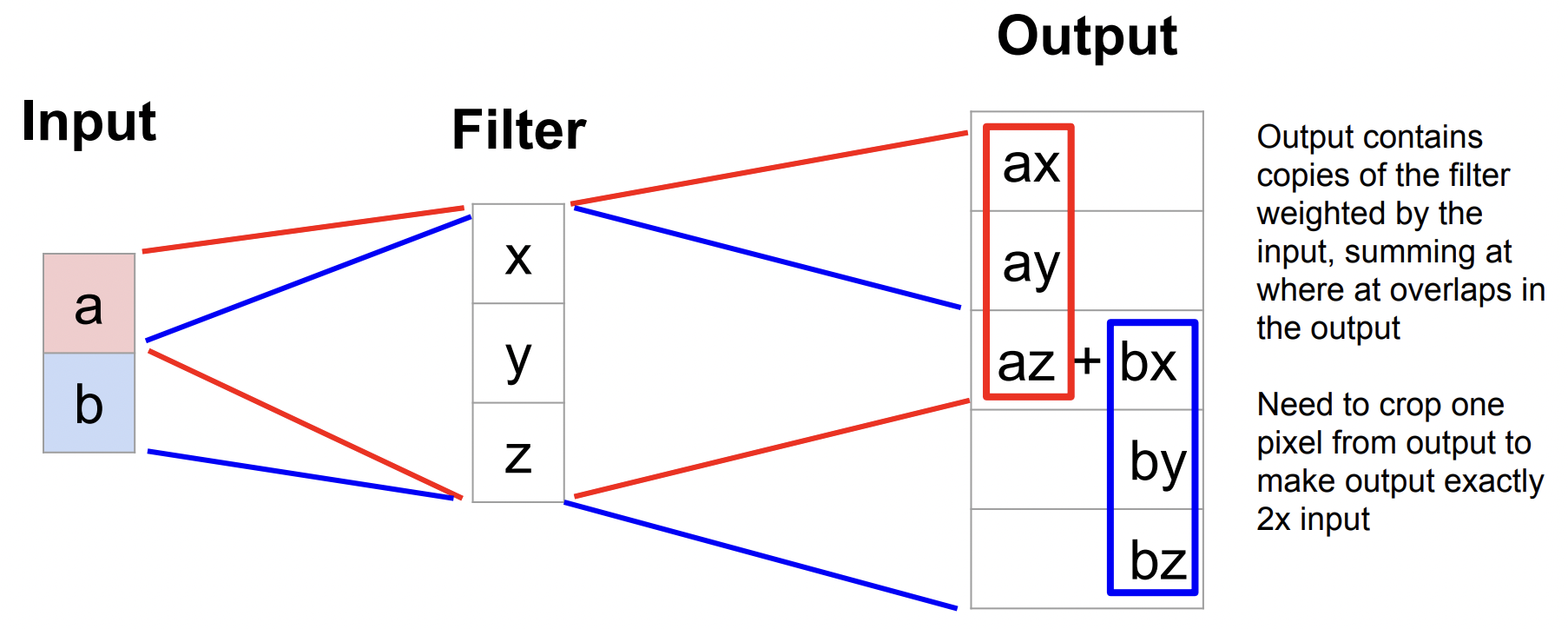
참고 자료 : https://dacon.io/forum/406022?page&dtype&ptype&fType
그리고 각 인코딩 영역과 디코딩 영역이 서로 수평관계에 있을 경우
각 영역의 결과물을 Concat한다.
아래는 한 블로그의 U-Net 설명이다.

Ⅲ. U-Net모델의 국룰 신경망 구조 사진을 보자.

사진으로 봤을 때 이해가 좀 더 잘되길 바란다.
Ⅳ. 이제 실습 코드를 보자.

복잡해 보이지만 차근차근 보면 쉽다.
1. 가장 멎저 Dataset을 매개변수로 하는 class를 선언했다.
2. 각각의 이미지 파일명을 오름차순으로 정리했다.
3. 데이터셋을 8:2비율로 나눴다. (# 80% 학습용, 20% 평가용)
4. 마지막으로 나중에 훈련셋 시험셋 비교를 위한 데이터셋 길이 함수 선언이다.

1. 이미지 세그멘테이션(image segmentation)을 활용한 데이터
mask에 리사이징하고, numpy 배열구조 float32타입으로 데이터를 변환했다.
2. 현재 [배경, 객체, 경계] 구조로 데이터가 형성되어 있는데
이를 [배경, 객체 + 경계] 구조로 변환하는 코드이다.
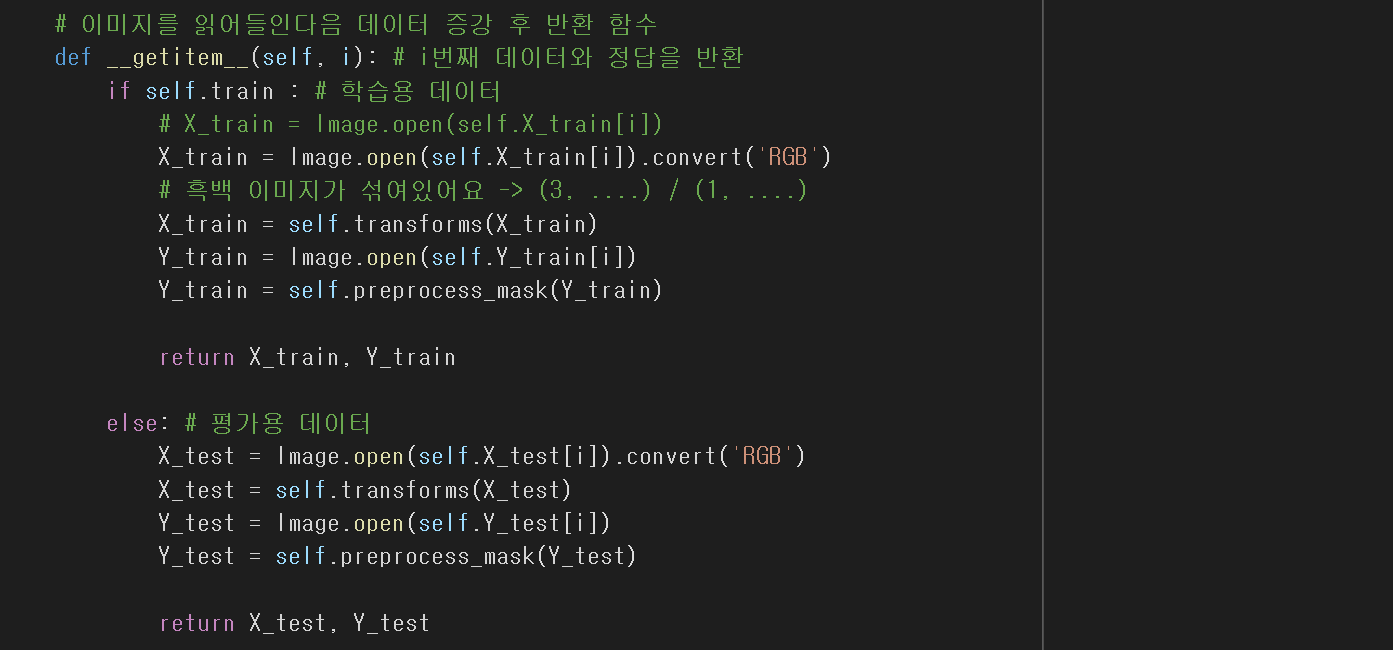
트레인 셋(preprocess_mask 처리된)과 테스트 셋(일반 이미지)
데이터를 받는 함수를 선언하는 과정이고
현재 transforms를 이용해 오버피팅 방지까지 된 과정이다.
❗❗❗채널이 다른 이미지가 섞여 있을 경우 ❗❗❗
위 과정에서 우리는 흑백이미지가 섞여 후에 문제가 생겼다.
때문에 .convert('RGB') 코드를 붙여 해결했다.
❗❗❗입력 채널 R,G,B 3채널로 고정. ❗❗❗
Ⅴ. U-Net 모델 정의
이번에는 따로 Class로 만들어 모델을 정의했다.
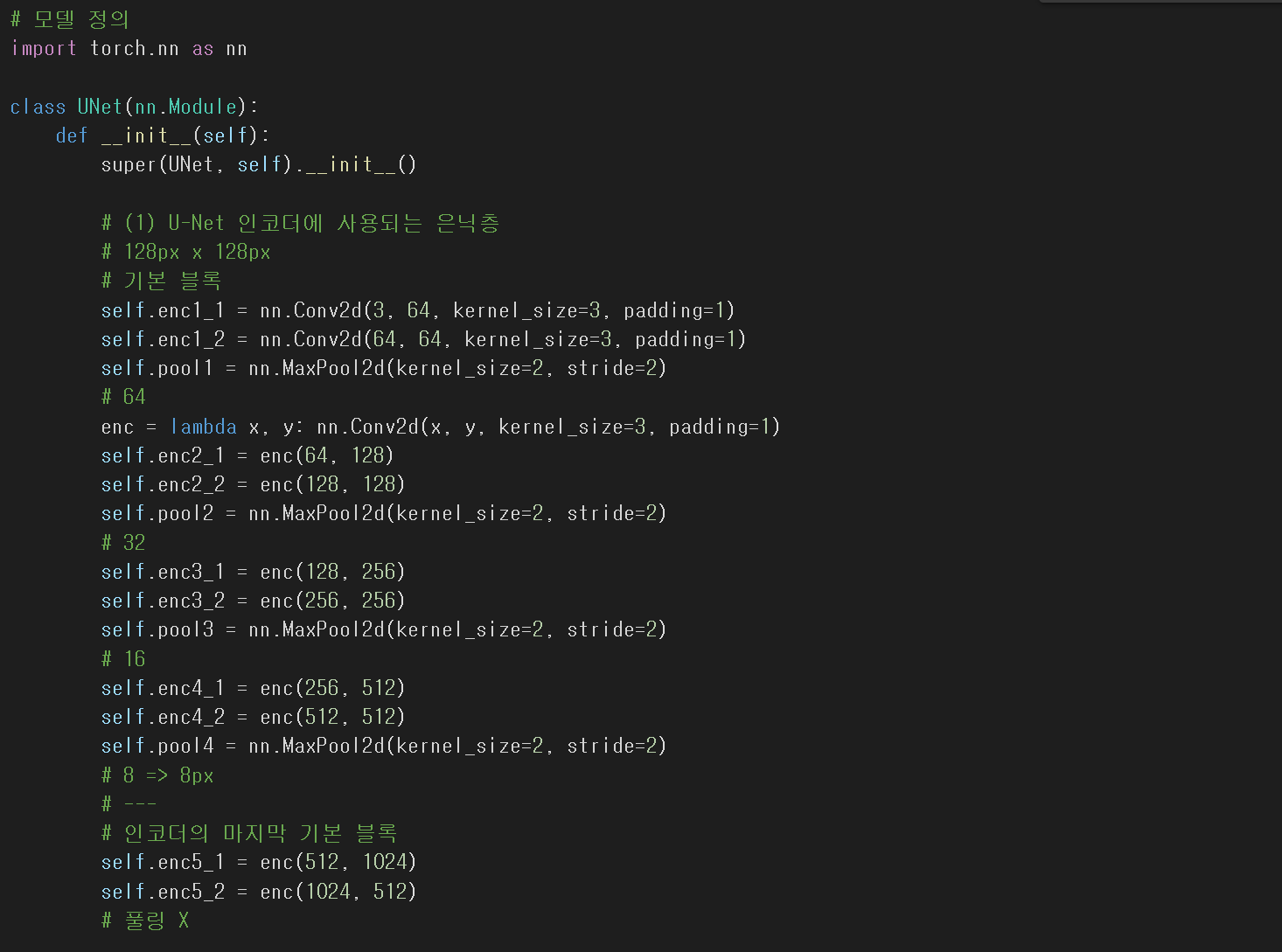
Encoder 블럭 정의
# enc는 인코더를 의미한다.
💡 enc = lambda x, y : nn.Conv2d(x, y, kernel_size=3, padding=1)
💡pooling layer : nn.MaxPool2d(kernel_size=2, stride=2)
# 인코더 층에서는 pooling layer를 사용한다!
위의 주석과 같이 인코더 블럭에서는
nn.Conv2d 에 커널은 3 * 3, padding =1적용해 사용했다.
그리고 풀링 블럭에서는
nn.MaxPool2d 를 사용하여 커널은 2 * 2, stride는 2씩 움직이게 했다.
데이터는 R,G,B채널 3개로 시작해
3 ▶ 64 ▶ 128 ▶ 256 ▶ 512 ▶ 1024 ▶ 512의 과정을 거친다.

Decoder 블럭 정의
# dec는 디코더를 뜻한다.
💡 dec = lambda x, y : nn.Conv2d(x, y, kernel_size=3, padding=1)
💡Upsample layer : nn.ConvTranspose2d(kernel_size=3, stride=2)
인코더블럭 / 디코더블럭 순전파 코드

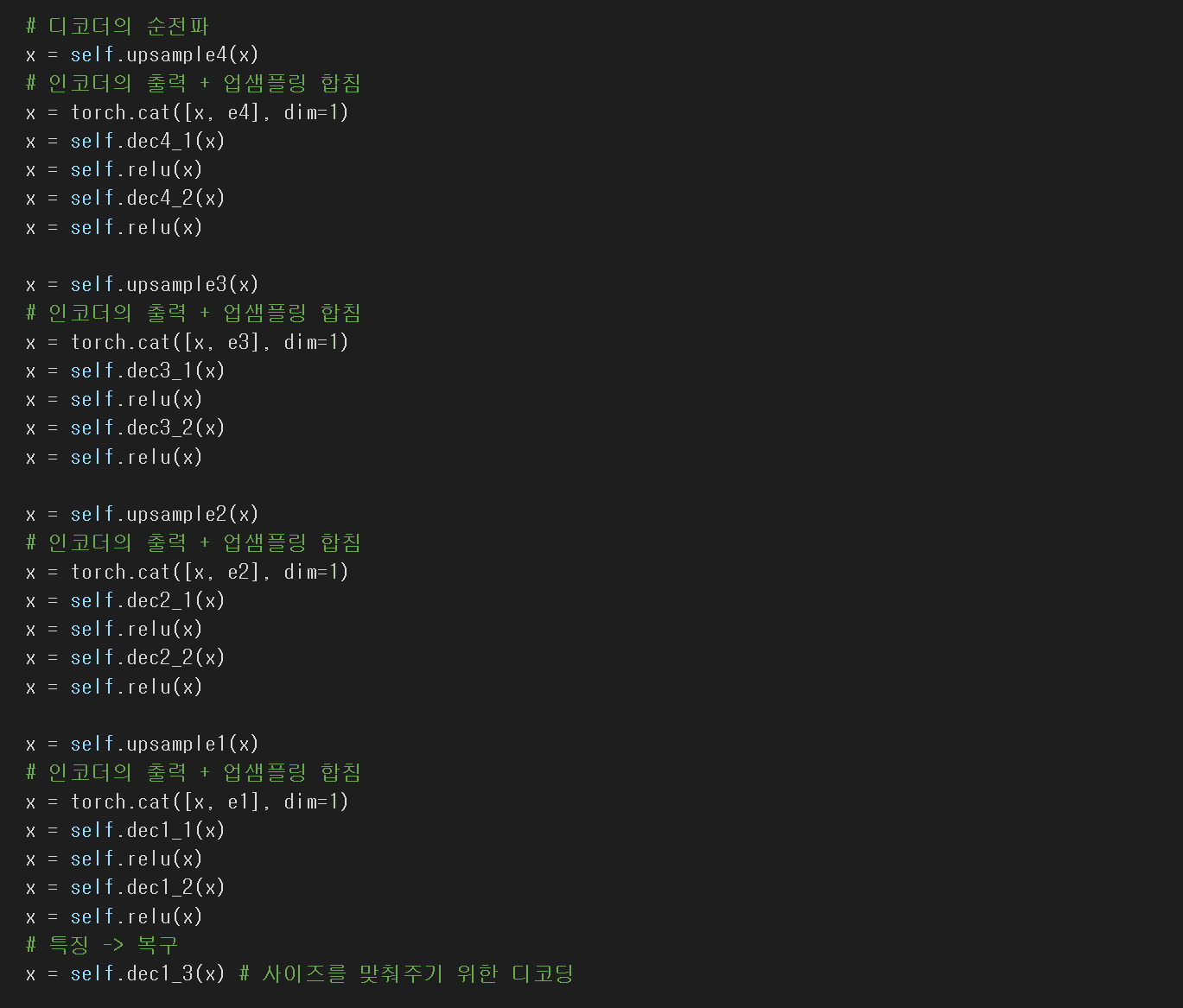
Ⅵ. 모델 학습 및 최적화 후 비교
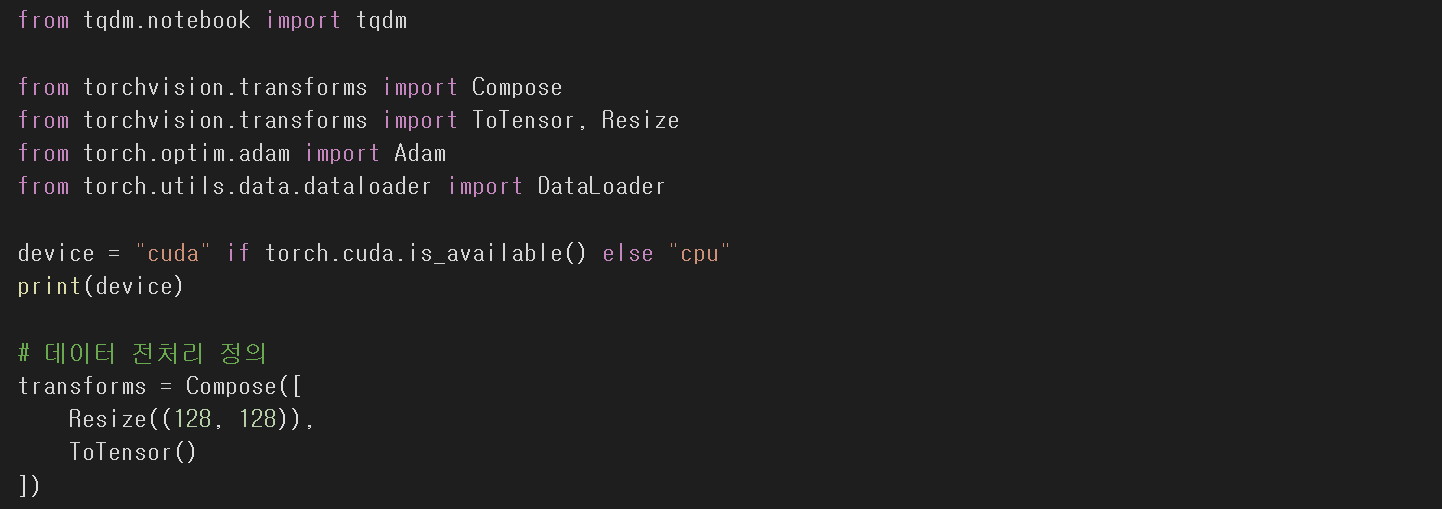
데이터 전처리를 위해 transforms를 정의한다.
- Resize (128, 128)
- ToTensor()
위에서 언급한 대로 8:2 비율로 데이터를 나눠준다.
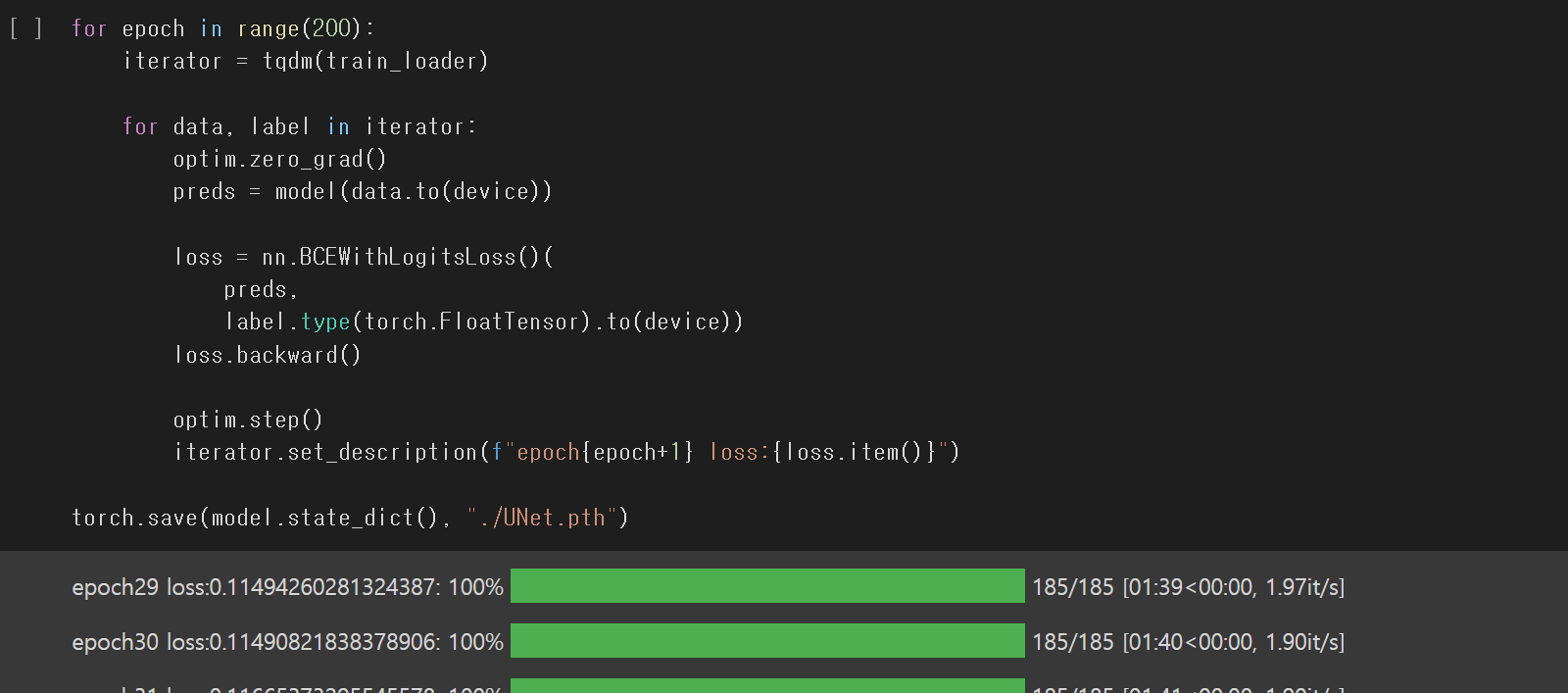
가중치 학습
For 문
- data , label에 대하여
- 기울기 초기화
- pred 는 data를 모델에 학습
- loss 는 nn.BCEWithLogitsLoss()를 pred와 label을 비교
- loss를 .backward() # 역전파
💡nn.BCEWithLogitsLoss()
Sigmoid layer + Cross Entropy
모델 평가
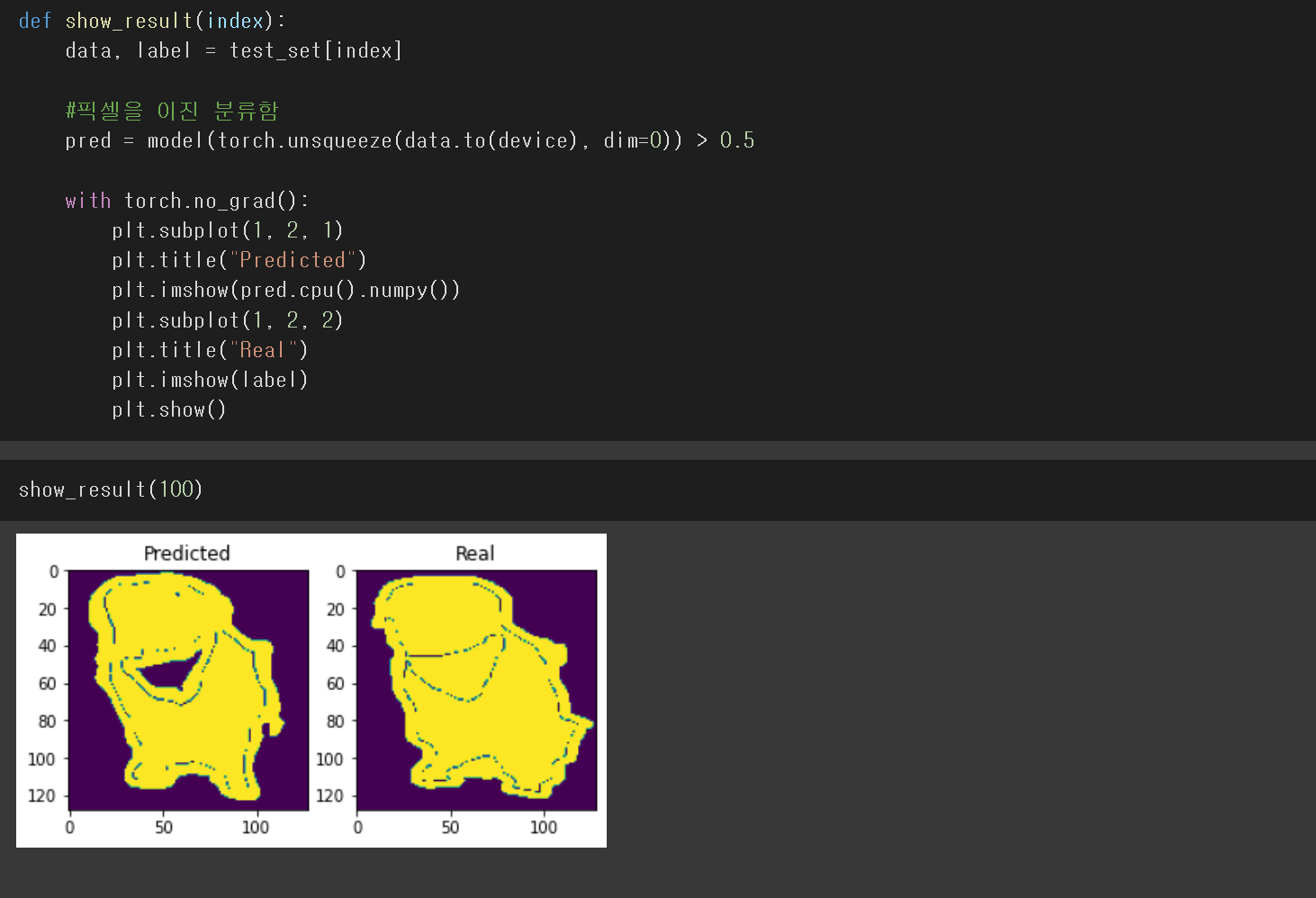
모델이 잘 학습됬는지 확인하기 위해
테스트 셋을 모델에 학습시키고
시각화에 도움이 되기위해 픽셀을 이진 분류해주고
100번째 사진을 비교하는 함수를 선언하고
plt.show()해주면 위와 같이 학습이 잘된것을 확인할 수 있다.
💡torch.squeeze or nn.unsqueeze
squeeze함수는 차원이 1인 차원을 제거해준다.
따로 차원을 설정하지 않으면 1인 차원을 모두 제거한다.
그리고 차원을 설정해주면 그 차원만 제거한다.
unsqueeze함수는 squeeze함수의 반대로 1인 차원을 생성하는 함수이다.
그래서 어느 차원에 1인 차원을 생성할 지 꼭 지정해주어야한다.
'Hello MLop > DL' 카테고리의 다른 글
| MLop_DL_LSTM 실습 (0) | 2022.12.18 |
|---|---|
| MLop_DL_RNN 실습 (0) | 2022.12.17 |
| MLop_DL_ResNet 실습 (0) | 2022.12.04 |
| MLop_DL_CNN 실습 (0) | 2022.11.30 |
| MLop_DL_손글씨 판단 예측 (0) | 2022.11.24 |



