20221123
36일차

RNN(Recurrent Neural Network)
입력과 출력을 시퀀스 단위로 처리하는 시퀀스(Sequence) 모델이다.
RNN하면 시계열데이터, 시퀀스 이 두 단어가 자주 등장하는데,
우선 두 단어에 대해 알아보고 넘어가자.
💡 시퀀스(Sequence)
시퀀스의 단어 뜻은 수열이다.
수열이란?
▶ 수 또는 다른 대상의 순서 있는 나열이다.
순서가 있다는 의미는 어떤 구분이 있다는 의미이고,
그 구분을 시간으로 정한게 바로 시계열이다.
💡 시계열(time series)
일정 시간 간격으로 배치된 데이터들의 수열을 말한다.
시계열 예측(time series prediction)
주어진 시계열을 보고 수학적인 모델을 만들어서 미래에 일어날 것들을 예측하는 것을 뜻한다.
결론적으로 위와 같은 특징을 가진 데이터를
잘 학습시키기 위해 생겨난 모델이 바로 RNN 모델이다.
그렇다면 RNN모델은 왜 시계열 데이터 분석에 강할까?
바로 모델 구조에 있다.
RNN모델은 유닛 # layer, 층, 블록 간의 연결이
순환적 구조를 갖는 특징을 갖고 있는데
아래의 그림을 보자.

그림을 보면 왜 순환신경망인지 이해할 수 있다.
시점 t에 데이터가 들어오면 Y로 RNN모델로 가중치를 받은
Yt가 생기고 이를 다음 시점 t+1로 넘겨준다.
즉, 예를 들어 설명하면월요일(t)에 주가를 연두색 블록에 넣는다.
그럼 RNN모델에서 가중치를 부여해 Y라는 블록에 저장하고이를 다시 화요일(t+1)에 넘겨준다.
그럼 월요일(가중치가 부여된)주가와 + 화요일(새로운 주가)의 데이터가다시 RNN모델에 들어가는것이다.
이를 다시 정리하면RNN모델의 기능을 이용해
이전 시점(t)과 다음 시점(t+1)을 기준으로 누적 계산하여가중치를 부여하는 것이다.
이렇게 쭉쭉 가다보면 일정 기간의 데이터의 변동을 가중치를 이용하여 학습하게 되는것이다.
= 뒤의 그림은 이를 풀어서 나타낸 그림이다.

✔ 순환 신경망은 추가적인 저장공간을 가질 수 있다.
✔ 이 저장공간이 그래프의 형태를 가짐으로써
시간 지연의 기능을 하거나 피드백 루프를 가질 수도 있다.
실제 실습 코드를 보자.

이번 실습은yfinance를 인스톨하여
일정 기간의 Netflix 주가를 뽑아

불러온 Netflix의 주가 데이터다.

전처리 후 <2015년~ 2018년의 Netflix>의 데이터다.

머신러닝에서의 독립변수
딥러닝에서의 입력층에 들어갈 데이터와
머신러닝에서의 종속변수
딥러닝에서의 정답 데이터를 나눠 주는 과정이다.

Netflix 데이터를 잘 쓰기위해
Class를 만들어 함수를 넣어주었다.
첫번째 __init__ 함수를 이용해
사용할 value들을 정리해 주었고
두번째 __len__ 함수를 이용해
우리가 넣을 데이터는 30일씩 묶어서 넣는다는 기능을 추가.
세번째 __getitem__함수를 이용해
30일치 데이터를 사용목적에 따라 분리해주는 기능을 넣었다.
입력층에 넣을 데이터를 정리하였으니.
받을 RNN블록을 정의해보자.

RNN Class를 새로 만들어
RNN 블록을 정의했다.
이번 RNN 딥러닝은
RNN블록 하나와 분류기로 사용될 Linear블록 2개를 이용해 구성했고
활성화 함수로 ReLU()를 넣어줬다.

마지막으로 RNN Class에
순전파의 기능을하는 함수 forward를 넣어주었다.
내용은 이러하다.
1. RNN층의 출력 # 출력값은 x
2. 출력값의 형태 변환
3. 분류기(fc1,fc2)로 분류 # 활성화 함수는 ReLU()
4. torch.flatten(x)

다음은 가중치 최적화(학습)을 위해
최적화함수(Optinizer) Adam과
batch_size까지 정해준 코드이다.
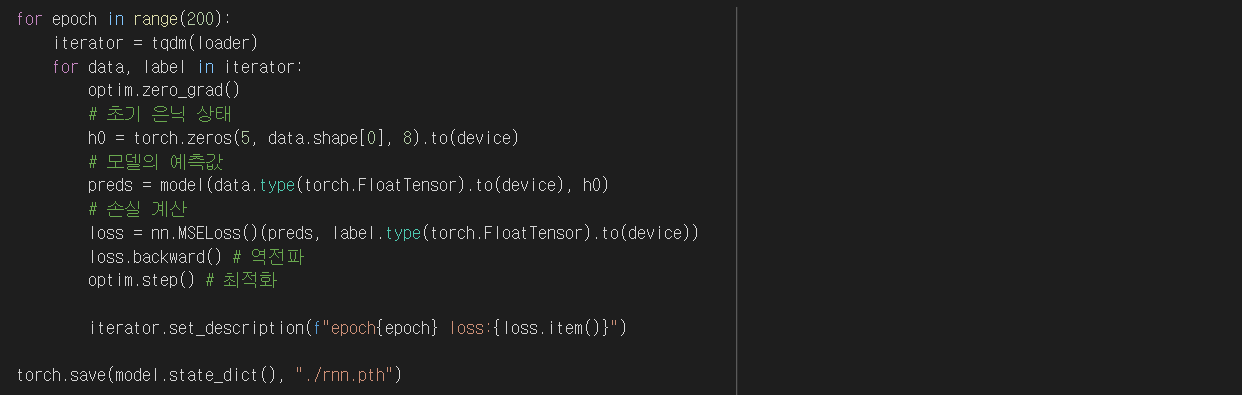
역전파 코드이다.
손실(loss)과 예측값(preds)를 정의해 주었다.

값 예측이므로 MSELoss()를 사용해서 비교했고
모든 결과값에 대한 평균 오차를 total_loss에 저장했다.

평균 오차는
0.0025xxxx
즉, 거의 없다는 것을 확인했다.

이를 시각화한 그래프이다.
파란선이 예측 값,
주황선이 실제 값이다.
'Hello MLop > DL' 카테고리의 다른 글
| NLP_RNN을 이용한 Encoder-Decoder (0) | 2023.01.23 |
|---|---|
| MLop_DL_LSTM 실습 (0) | 2022.12.18 |
| MLop_DL_U-Net 실습 (0) | 2022.12.05 |
| MLop_DL_ResNet 실습 (0) | 2022.12.04 |
| MLop_DL_CNN 실습 (0) | 2022.11.30 |



