2023.01.18

RNN에서
다 대 일(many-to-one) 구조로 텍스트를 분류할 수 있고
다 대 다(many-to-many) 구조로는 개체명 인식이나 품사 태깅과 같은 문제를 풀 수 있었다.
이번에 포스팅할 내용은
하나의 RNN은 인코더, 하나의 RNN은 디코더로 연결해서 사용하는
인코터-디코더 구조이다.
인코더-디코더 구조는 주로 입력 문장과 출력 문장의 길이가 다를 경우에 사용하는데
대표적인 분야로 번역기, 텍스트 요약이 있다.
즉, 영어 문장을 한국어로 번역할 때
당연히 입력 문장과, 출력 문장의 길이가 다르다.
텍스트 요약은
당연히 요약이기 때문에
입력 문장이 길고 출력 문장이 짧을 것이다.
✨ Auto Encoder ✨
auto encoder는 비지도 학습(unsupervised learning)으로
입력 데이터를 압축시켜 다시 확장하여
결과 데이터를 입력 데이터와
동일하도록 만드는 일종의 딥 뉴럴 네트워크 모델이다.

인코더 구간(encoder) = h
✔ 입력(x)의 정보를 최대한 보존하도록 손실 압축을 수행
✔ 뉴런 수를 입력층보다 작게하여
데이터를 압축하는 역할을 한다.
즉 입력(x)에 대한 feature vector라고 할 수 있다.
디코더 구간(decoder)
✔ 중간 결과물(h)의 정보를 입력(x)과 같아지도록 복원(압축 해제)을 수행
✔ 보통 MSELoss를 통해 최적화 수행
오토 인코더(Auto Encoder)는 압축과 해제를 반복하며
특징 추출을 자동으로 학습한다.
✨ Sequence - to - Sequence ✨
이름 그대로 sequence를 다시 sequence로 내보내는 것을 말한다.
sequence를 해석하면
순서 있는 나열이라는 뜻인데
시간을 구분으로 sequence를 만들면
시계열
자연어를 토큰화 해서 sequence를 만들면
자연어 문장이 된다.
이러한 순서가 있는 데이터를
다시 순서가 있는 데이터로
바꿔주는게 sequence - to - sequence모델인데
포스팅의 처음에도 설명했듯이
목적( =번역, 요약등)에 따라
여러 형태로 쓰일 수 있다.
가장 기본적인 번역의 기능을 해주는seq2seq모델을 통해구조를 알아보자.

위의 사진을 보면
하나의 sequence 데이터가 들어가서
모델 알고리즘을 거쳐
새로운 sequence 데이터로 나오는 것을 알 수 있다.
이게 우리가 일상에서 접하는
번역의 원리이다.
이를 조금더 자세히 보면

첫번째 사진에서 보았던sequence모델의 내부이다.
인코더 - context - 디코더 구조로 되어있다.앞서 보았던 autoencoder의 경우
입력과 출력의 모양이 같았지만
seq2seq모델의 경우상황과 목적에 따라 입,출력 모양이 다르게 나올 수 있다.
인코더는 입력 문장의 모든 단어들을 순차적으로 입력받고
마지막에 이 모든 단어의 정보들을 압축해서 하나의 벡터로 만든다.
이를 Context Vector라 한다.
이러한 Context Vector를 디코더에게 전달하면
번역된 단어를 한 개씩 순차적으로 출력한다.
그럼 어떻게 인코더는 vectorizing 시키고
디코더는 어떻게 이를 번역해서 단어로 내보낼까?
이 부분에서 RNN계열의 알고리즘이 등장한다.
RNN의 핵심은 재귀를 통해 순서의 확률을 내놓는다.
조금 더 자세히 보자.

RNN계열의 모델 알고리즘은 위와같은
재귀적인 학습을 통해 각 순서별로 확률을 계산해 학습한다.
이를 인코더라는 기능하에
적용 시키면 I am a student의 순서를 학습했을 것이고
이를 Vectorizing( # Context)하여 다시 디코더로 넘겨주고
번역된 문장으로 학습 시키고 ( # 교사 강요)
수 많은 Case가 훈련 된다면
마침내 번역 기능을 하는 모델이 만들어 지는 것이다.
이런 궁금증이 생길 수 있다.
아니, Context vector에 있는 값들이
어떻게 바로 내가 원하는 번역어로 선택되는가?
이 질문에 대한 정답은 바로
디코더에 있는 softmax 활성화 함수 이다.
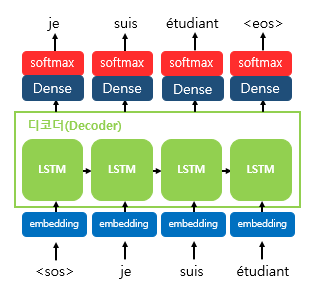
디코더에서 각 시점의 RNN셀에서 출력 벡터가 나오면,
해당 벡터는 softmax함수를 통해
출력 시퀀스의 각 단어별 확률값을 반환하고
디코더는 출력 단어를 결정한다.
💡 Softmax 활성화 함수

Sequenc의 개념과
encoder, decoder개념을 잘 이해하여
RNN계열의 모델을 이용한응용?느낌의 모델을 알아보았다.
다음은 Attention이다.

'Hello MLop > DL' 카테고리의 다른 글
| NLP_Transfomer (0) | 2023.02.11 |
|---|---|
| NLP_어텐션 메커니즘(Attention Mechanism) (0) | 2023.01.23 |
| MLop_DL_LSTM 실습 (0) | 2022.12.18 |
| MLop_DL_RNN 실습 (0) | 2022.12.17 |
| MLop_DL_U-Net 실습 (0) | 2022.12.05 |



