20221124
37일차

LSTM(Long Short-Term Memory)
장단기 메모리
시계열 데이터, 순서가 있는 데이터를 학습시키면서
우리는 한가지 불편함을 느끼게 된다.
한가지 예를 들어보겠다.
"꽃이 화려하게 피어있는 마당은 내일 일기예보에서 말한대로 비가 올것입니다."
이 문장을 RNN모델에 학습시켜
문장속에서 날씨 정보를 획득하고 싶다.
즉, 내가 원하는건 "내일 비가 올것입니다"
이 세가지 인데
불필요한 문장이 사이사이 많다는것이다.
즉, 순환 구조를 이용해 순서대로 학습하는 RNN모델은
불필요한 데이터 까지 학습해 가중치가 불필요하게 부여된다는 한계를 보여주는 것이다.
💡 = 기울기소실문제를 야기한다. ⭐⭐⭐⭐⭐
이와 같은 시퀀스 계열의 데이터의 학습에서
LSTM은 단계별 선별을 하는 기능을 넣어 점점 우리가 원하는 데이터만 뽑아 낼 수 있게발전된 시퀀스 데이터 학습 모델이다.
💡 LSTM의 구조
LSTM의 구조는 아주 특별하게 구성이 되어있다.
데이터는 t-1시점에서 t시점으로 흘러 가는데
그때 단계 별로 활성화 함수를 이용해 선별하여 업데이트 해준다.

1. 첫 번째 파트
시그모이드 함수를 통해 데이터를 버릴지 말지 정한다.
즉,
"꽃이 화려하게 피어있는 마당은 내일 일기예보에서 말한대로 비가 올것입니다."
문장에서 "꽃이(t-1 시점) 화려하게(t 시점)" 이라 가정한다면,
t시점에서 "꽃이(t-1 시점)"을 버릴건지 안버릴 건지 확인하는 것이다.
2. 두 번째 파트
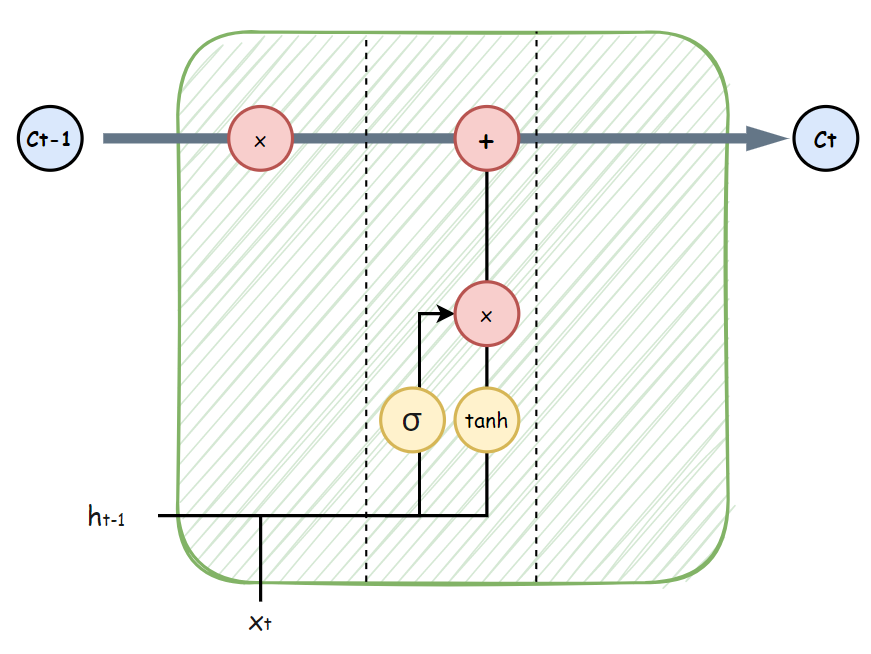
두 번째 파트에선
전의 결정을 토대로
흘러가고 있는 C 데이터에 업데이트 해준다.
즉,
t시점에서 "꽃이(t-1 시점)"을 버리기로 했다면,
결정한 특징을 업데이트 시켜주는 파트이다.
3. 세 번째 파트
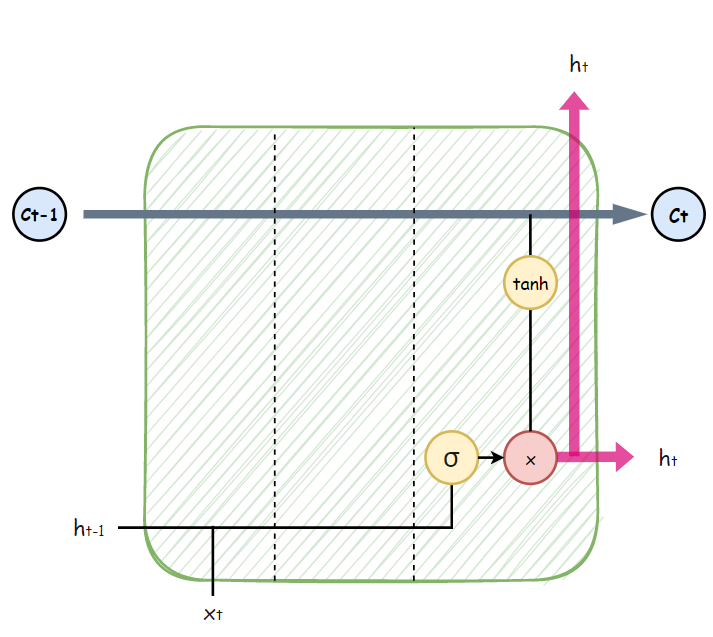
이제 Ct-1에서 부터 흘러가고 있는 업데이트된 값을
tanh 활성화 함수를 통해 받고
ht라는 가중치와 함께 Ct # 다음 시점로 보내준다.
위와 같은 구조를 가진
LSTM모델은
셀(Cell)이라는 공간을 통해
시그모이드 함수로는 추가, 삭제 기능을 부여하고
하이퍼볼릭 탄젠트 함수로는 값을 Update하여
불필요한 데이터를 걸러
기울기 소실을 방지한다. ⭐⭐⭐⭐⭐
이제 실습 코드를 보자.
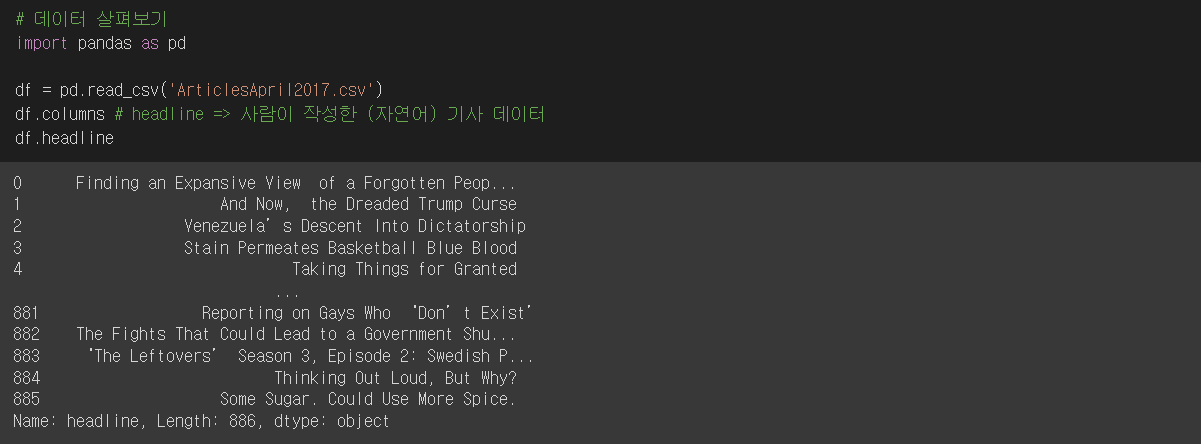
데이터로는 kaggle의 기사 헤드라인 데이터를 받아왔으며
아래는 TextGeneration라는 전처리 Class를 선언하여객체로 각각의 전처리 함수를 선언한 코드이다.

▲ 첫 번째로 특수문자 제거 함수를 선언하고

필요한 전처리를 위해
glob을 이용해 필요한 부분을 리스트로 받았다.

이제 자연어로 구성된 문장을 시계열 데이터로 만들기 위해
순서를 부여해야하는 과정이다.
먼저 glob으로 뽑아온 것들을
생성자(__init__)로 불러
unknown 값과, 구두점을 제거하고
각각의 단어에 고유번호를 지정하는
.BOW로 처리 하는 함수를 선언하였다.

전처리된 헤드라인 값들을
space(띄어쓰기)를 기준으로 스플릿 하고 난 후
이러한 데이터가 있을 수 있다.
ex) ["단어 + 단어 + 단어" , "단어"....]
우리는 단어 + 단어가 들어오면 다음 단어에 영향을 미쳐야하는
# LSTM모델에 넣어야 하기에
입력값 형태로 만들어야 하기에
for문을 이용해 처리하는 함수이다.

마지막으로
데이터 개수를 반환하는 함수와
데이터를 불러오는 함수를 선언해
전처리 Class정의를 마쳤다.
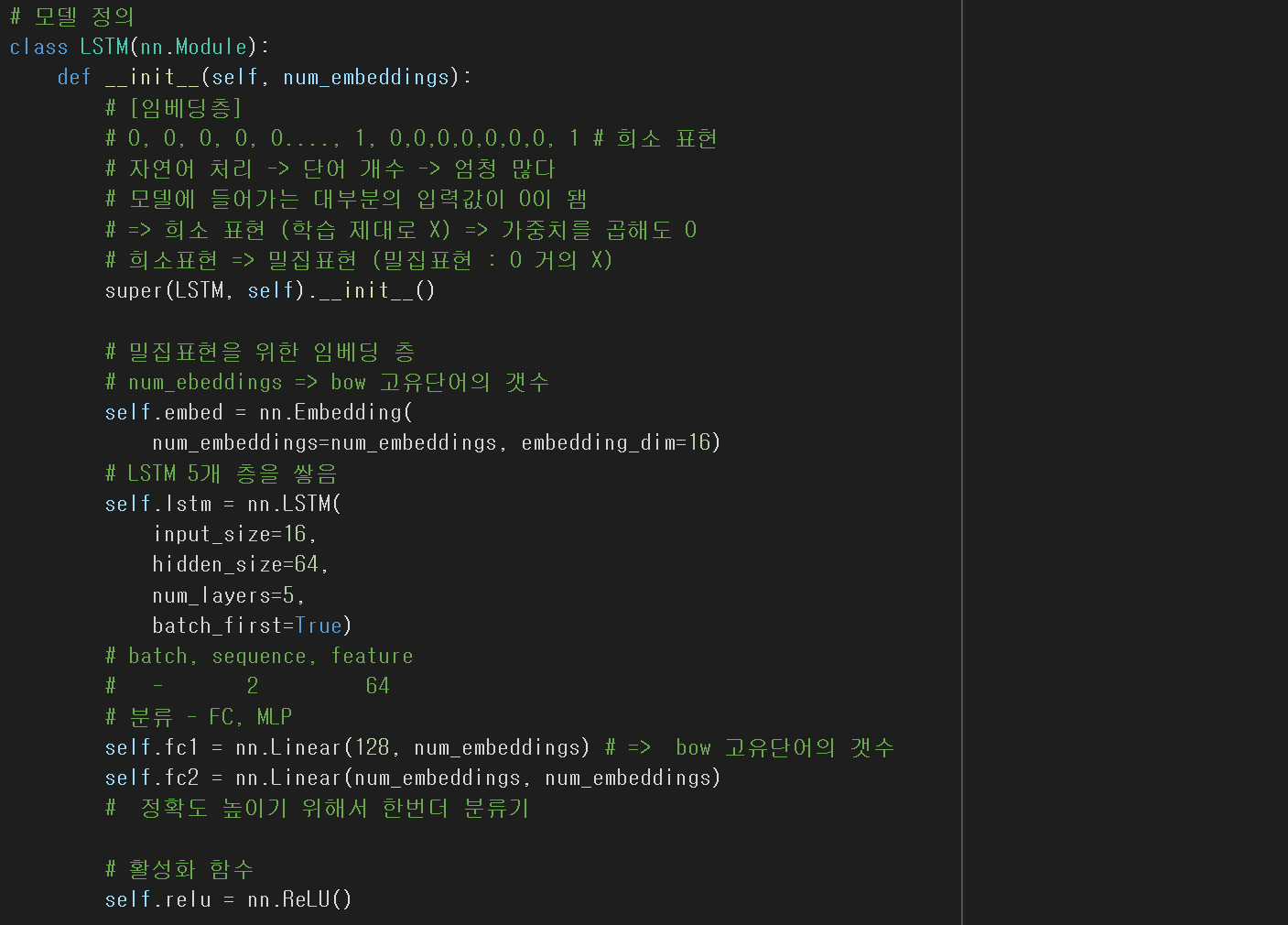
이제 모델 정의를 위해
LSTM Class를 정의해 준다.
첫번째로
nn.Embedding()을 통해
무수히 많은 단어들을 임베딩 벡터로
학습하게끔 만들어 준다.
두번째로
LSTM층 정의이다.
총 5개의 LSTM층을 만들어 선별하게 했다.
마지막으로
nn.Linear를 사용하여
분류 해주는 활성화 함수 생성
그리고
ReLU() 생성
# 값을 넘겨주는 역할.

순전파 함수선언이다.
1. 임베딩
2. LSTM층 # 5개 층
3. 선별하고자 하는 데이터(x)와 나머지 데이터로 나누기
4. 분류 # Linear()
순서이다.
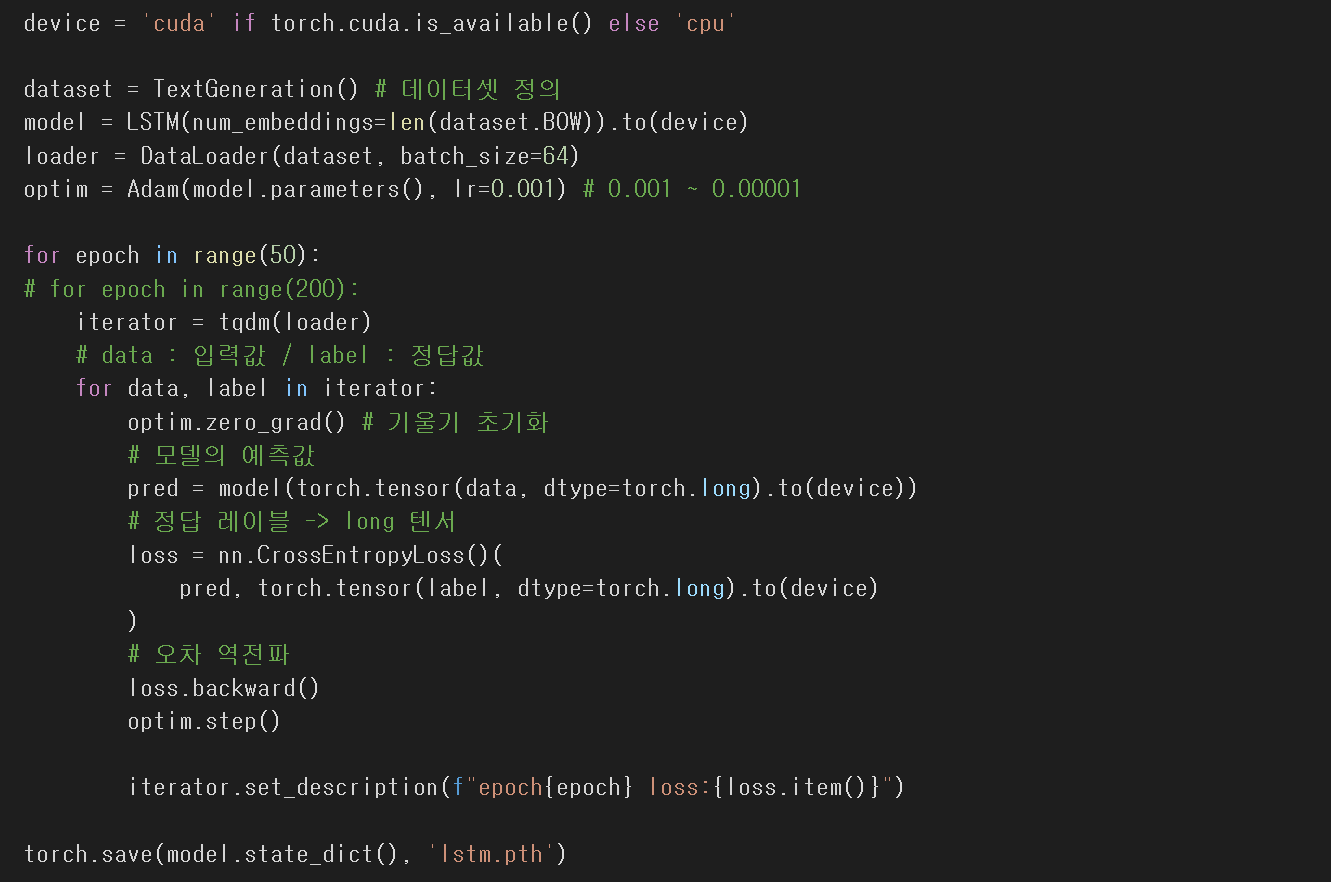
러닝 코드이다.
데이터셋 정의
모델 정의 # LSTM # dataset.BOW 사용
최적화함수 Adam
50번 학습순서
1. 데이터와 라벨로 나누고
2. 기울기 초기화
3. 예측값은 모델에 data를 넣어서 학습
4. 손실계산은 CrossEntropyLoss()
5. 오차 역전파
6. 최적화 Adam사용

Loss가 3.7890xxx 까지 줄어든것을 확인할 수 있다.
학습된 모델을 통해
유의미한 모델이 되었는지 직접 출력해 보자.
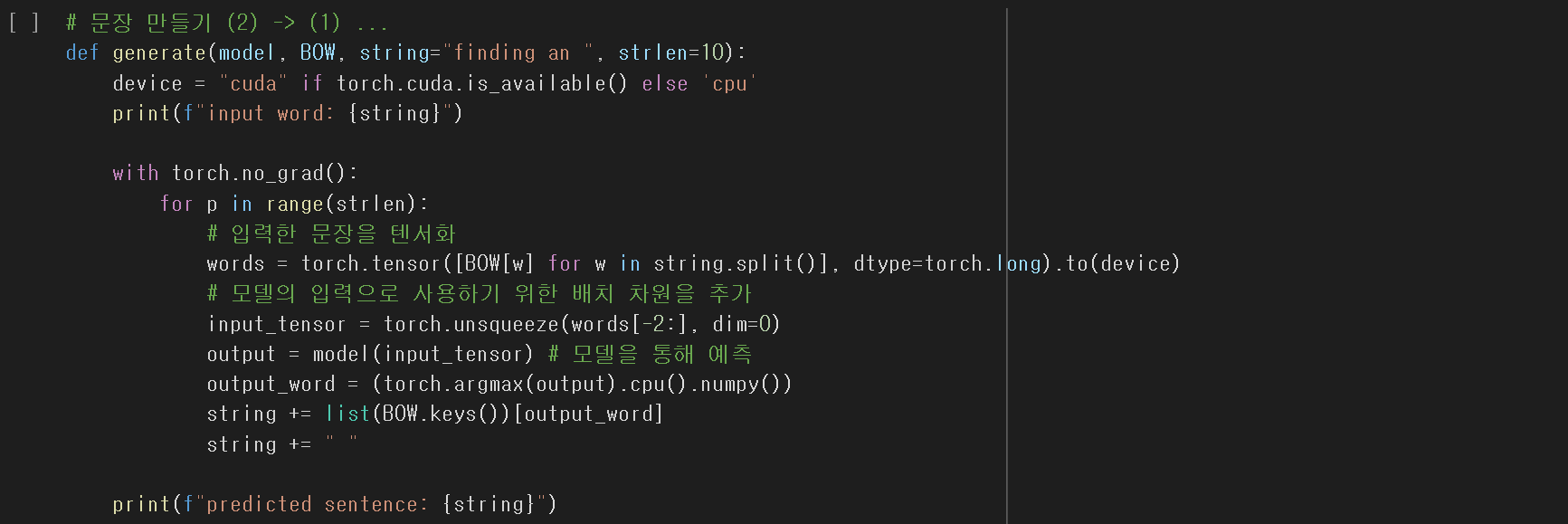
이 역시 모델 훈련할때의 데이터 전처리 내용을지켜 모델에 넣어줘야 한다.
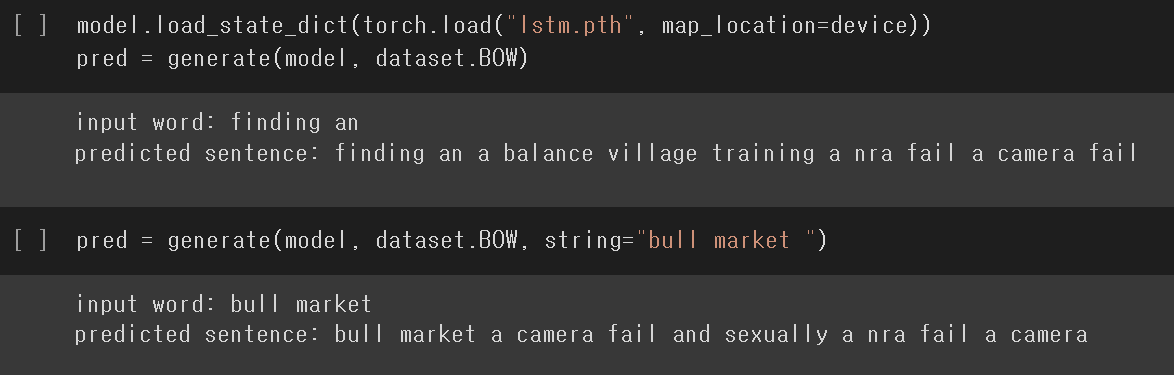
완벽하진 않지만
원하는 결과가 나왔음을 확인할 수 있다.
'Hello MLop > DL' 카테고리의 다른 글
| NLP_어텐션 메커니즘(Attention Mechanism) (0) | 2023.01.23 |
|---|---|
| NLP_RNN을 이용한 Encoder-Decoder (0) | 2023.01.23 |
| MLop_DL_RNN 실습 (0) | 2022.12.17 |
| MLop_DL_U-Net 실습 (0) | 2022.12.05 |
| MLop_DL_ResNet 실습 (0) | 2022.12.04 |



