20230130


Attention is all you need
2017년 Google에서 발표한
transformer 하면 떠오르는 대표적인 논문이다.
논문은 제목부터
연구의 내용을 독자에게 던진다.
'Attention Is All You Need'
'어텐션은 네가 필요로 하는 전부이다.'
'어텐션이면 충분해'라는
내포된 의미도 가지고 있다고
개인적으로 생각한다.
왜 어텐션이면 충분하다는
제목을 붙여 나왔을까?
바로 Transformer의 핵심 포인트인
Seq2Seq 기반의
Attention Mechanism만을
사용한 모델이기 때문이다.
이게 무슨 말인지
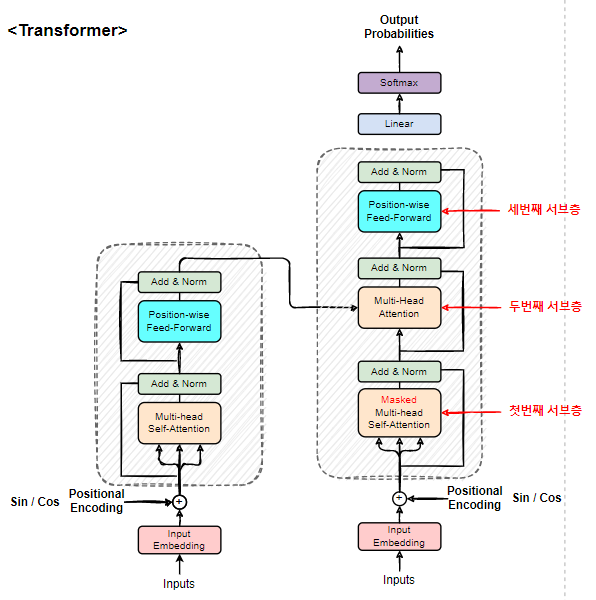
Transformer의 구조를 보자.

가장 먼저 눈에 띄는 점은
Recurrent 모델이 사라졌다는 점이다.
# RNN, LSTM, GRU...
그리고 논문 제목처럼
모델의 구조가 Attention층으로만
구성되어있다.
여기서 우리는 의문이 생긴다.
자연어 처리에서
문장이 들어왔을 때
인코더-디코더 구조에서
문장의 단어(토큰) 순서대로
모델은 학습을 한다.
그럼 Transformer는
어떻게 Attention Mechanism 만으로
단어의 순서를 컴퓨터에게 전달했을까?
✨ Positional Encoding ✨
RNN이 자연어 처리에서 유용했던 이유는
단어의 위치에 따라
단어를 순차적으로 입력
받아서 처리하는 RNN의 특성으로 인해
각 단어의 위치 정보(Position information)를
가질 수 있다는 점에 있었다.
하지만 트랜스포머는
Attention으로만 이루어져 있음으로
단어의 위치 정보를
다른 방식으로 알려줄 필요가 있다.
이를 위해 트랜스 포머는
각 단어의 임베딩 벡터에
위치 정보들을 더하여
모델의 입력으로 사용한다.
이를 Positional Encoding이라 한다.

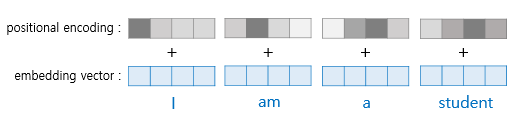
그렇다면 Transformer에서는
어떻게 각 토큰들에 순서를 부여했을까?
# Positional Vector 구성을 어떻게 했을까?
논문에서는 크게 3가지로 해결과정을 보여준다.
1. 시퀀스 크기에 비례해서 일정하게 커지는 정수값 부여
→ 단어보다 위치 정보가 커져 단어의 의미가 훼손됨
→ 위치 벡터가 특정한 범위를 갖고 있지 않아서 모델의 일반화 불가능
2. 첫 번째 토큰부터 마지막 토큰까지 0~1 사이 값으로 부여
→ 시퀀스 길이에 따라 같은 위치 정보에 해당하는 위치 벡터값 달라짐
3. 주기함수 sin&cos 함수 사용하기
→ 같은 위치의 토큰은 항상 같은 위치 벡터값을 가져야 하고
서로 다른 위치의 토큰은 위치 벡터값이 달라야 한다.
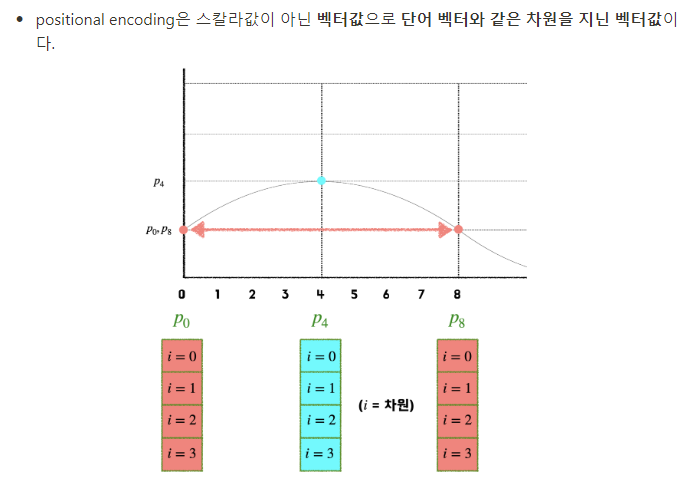
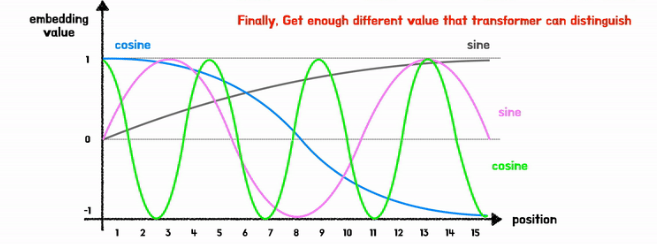
→ 하지만 주기함수이기에 서로 다른 위치에 같은 위치 벡터값이 결정됨
→ 고로 서로 다른 모양의 sin&cos 함수를 번갈아 가며 위치 벡터값을 정해줌
아래는 위 Positional Encoding 수식이다.
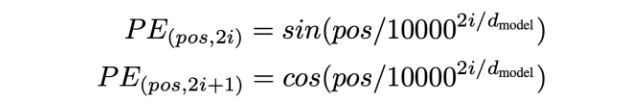
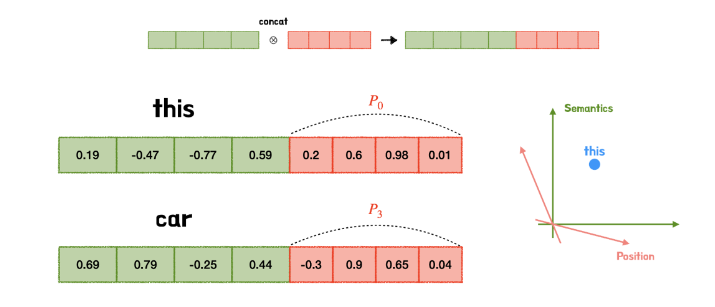
💡 Summation or Concatenate?
위로부터 얻은 단어 벡터와 위치 벡터값을
연산과정을 거쳐야 하는데
이때 Summation 방식을 이용한다.
Why?
단어 의미 정보와 위치 정보 간의 균형을 잘 맞출 수 있다.
Concatenate를 사용할 경우
단어 의미 정보와 위치 정보가 연결되는데
이는 직교성질(orthogonal)에 의해
서로 전혀 관계없는 공간에 있게 된다.
또한 정보가 뒤섞이는 문제가 발생할 수도 있다.
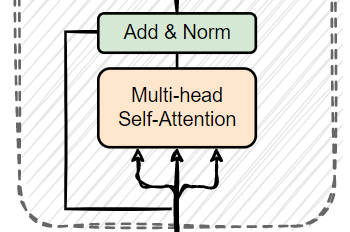
✨ Multi-Head Self-Attention ✨
Transformer의
Attention Layer에서는
Self-Attention이 이루어지는데 ⭐⭐⭐⭐
Quary, Key, Value를 이용해서
Attention Mechanism을 시행한다.
💡 Self-Attention의 Quary, Key, Value
Quary : 입력 문장의 모든 단어 벡터들
Key : 입력 문장의 모든 단어 벡터들
Value : 입력 문장의 모든 단어 벡터들
그전에 주요 파라미터의 개념을 보자.
🔥 Transformer의 주요 하이퍼 파라미터
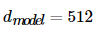
위의 d_model은
트랜스포머의 인코더와 디코더에서
정해진 입력과 출력의 크기를 의미한다.
임베딩 벡터의 차원 또한 d_model이다.
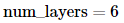
트랜스포머에서
하나의 인코더와 디코더를 층으로 생각했을 때
몇 층을 쌓았는지 의미한다.
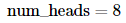
트랜스 포머에서는
Attention Mechanism을 사용할 때
병렬로 어텐션을 수행한다.
이때의 병렬의 개수를 의미한다.
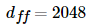
트랜스 포머의 내부에 있는
피드 포워드 신경망의
은닉층의 크기를 의미한다.
위의 파라미터를 참고해서
아래의 사진을 보면
"I will be back"이라는 문장이 들어왔을 때
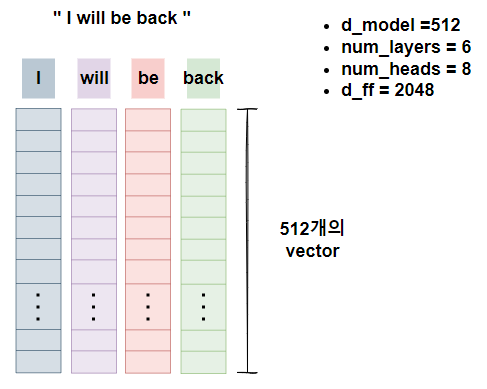
각각의 토큰들은 임베딩 과정을 거치고
Positioning Encoding까지 더해져
위와 같은 형태로 존재하게 된다.
💡 Q, K, V vector 얻기
Attention Mechanism에서
가장 중요한 Q,K,V 벡터는 어떻게 얻을까?
Q,K,V 벡터는
각 단어로 부터 얻게 되는데
이는 초기 입력인 d_model의 차원을 가지는
단어 벡터들보다 더 작은 차원을 가진다.
Transformer는 d_model을 num_heads로 나눈 값을각 Q, K, V vector의 차원으로 결정한다.
하지만 각 단어로 Q, K, V vector를 구해도 되지만
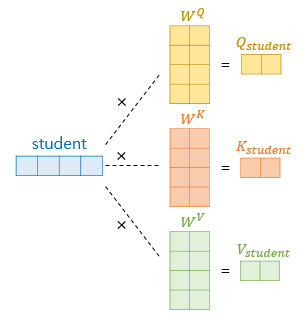
행렬 연산으로 구하면 일괄 계산이 된다. ⭐⭐⭐⭐⭐
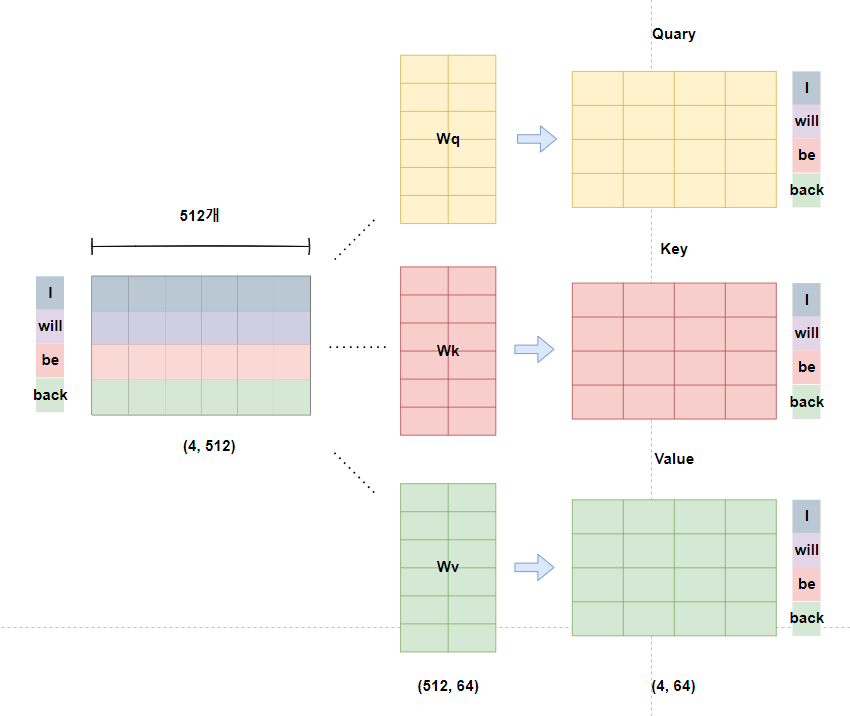
위의 사진에서 은닉층 행렬의 크기가
실제 수치와 다르게 표현됐지만
연산이 어떻게 되는지 알아보자.
행렬곱 연산으로 인해
(4 , 512) X (512 , 64)
= (4 , 512) X (512 , 64)
= (4, 64)가 되어
각각의 Q, K, V행렬은(4, 64) 모양의 행렬을 갖게 된다.
이제 구해진 Q, K, V행렬로Attention Value를 구하는 것을그림으로 보면
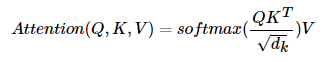
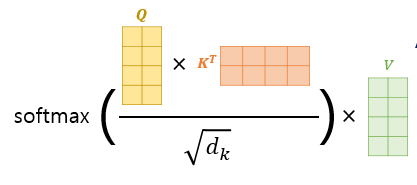
위와 같이 나온다.
Multi-Head Attention이란위의 과정을 병렬계산을 시키는 것이다.
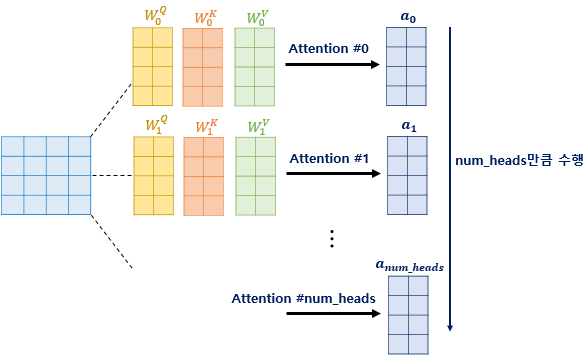
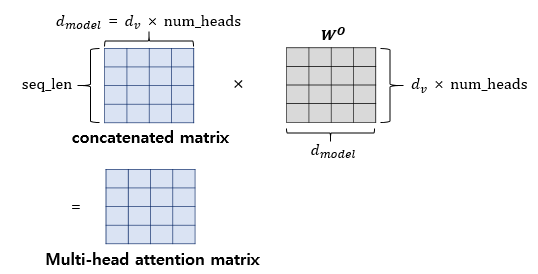
이렇게 병렬계산되어 나온 결과를
모두 연결하여 또 다른 가중치 행렬 W0을 곱해주면
비로소 Multi-head attention matrix가 나온다.
✨ Feed Forward Layer ✨
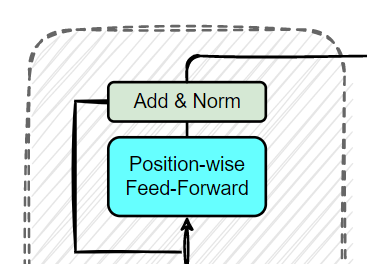
Feed Forward 신경망은
# 포지션 와이즈 피드 포워드 신경망 (두번째 서브층)
outputs = tf.keras.layers.Dense(units=dff, activation='relu')(attention)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)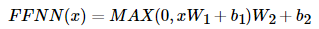
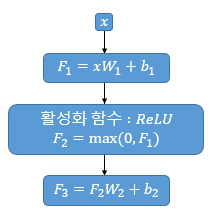
위의 코드에서도 볼수 있듯이
앞서 정해놓은 d_ff 파라미터를 적용해
데이터를 확장 시켰다가
ReLU 함수로 걸러주고
다시 원래의 사이즈로 맞춰주는 역할을 한다.
# 개인적으로 Vision에서의 Max-풀링층(pooling)이라 생각한다.
✨ 잔차 연결 & 정규화 ✨
잔차 연결(residual connection)
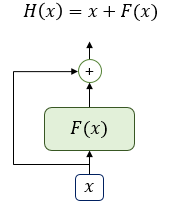
잔차 연결이란
서브층의 입력과 출력을
더하는 것을 의미한다.
Transformer에서
서브층의 입력과 출력은
동일한 차원을 갖고 있으므로
서브층의 입력과 출력을 더할 수 있다.
왜 더해주는 것일까?
바로 Res_Net에서 나온
Skip Connection과 같이
많은 연산시 가중치가 흐려지는것을 방지하기 위해
자꾸 보충해 준다고 생각하면 편하다.
만약 멀티 헤드 어텐션의 입력과 결과를 더한다면,
결과는 아래와 같다.
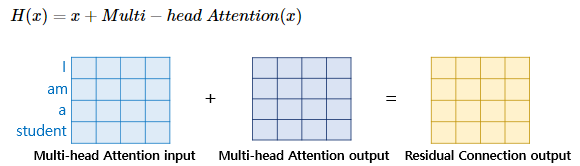
이렇게 잔차연결만 하면
결국 값의 크기들이
들쑥날쑥해지는데,
이를 다시 정규화(Norm) 해준다.
💡 층 정규화(Layer Normalization)
잔차 연결과 층 정규화 두 가지 연산을
모두 수행한 후의 결과 행렬을 LN이라 했을때
수식은 아래와 같다.
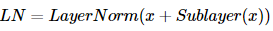
층 정규화는
텐서의 마지막 차원에 대해 평균과 분산을 구하고
# 텐서의 마지막 차원 = d_model
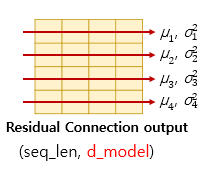
각 화살표 방향의 벡터()를
정규화 한 후 나타내는 수식은 아래와 같다.
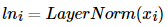
💡 층 정규화의 두가지 과정
1. 평균과 분산을 통한 정규화
우선, 평균과 분산을 통해 벡터 를 정규화 해주고
각 k차원의 값이 다음의 수식에 의해 정규화
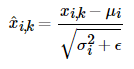
# ϵ (입실론) 은 분모가 0이 되는 것을 방지하는 값이다.
2. 감마(γ)와 베타(β)를 도입
초기값이 각각 1,0인 γ(감마) β(베타)라는 벡터를 준비한다.

이를 층 정규화 최종 수식에 합쳐주면
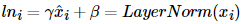
위와 같은 최종 수식이 나온다.
# 감마와 베타는 학습 가능한 파라미터.
이렇게 인코더층에서의
Context 학습을 끝내고
# 인코더 층에서의 유의미한 학습.
이를 다시 디코더층의
두번 째 Multi-Head Attention에
전달해준다.
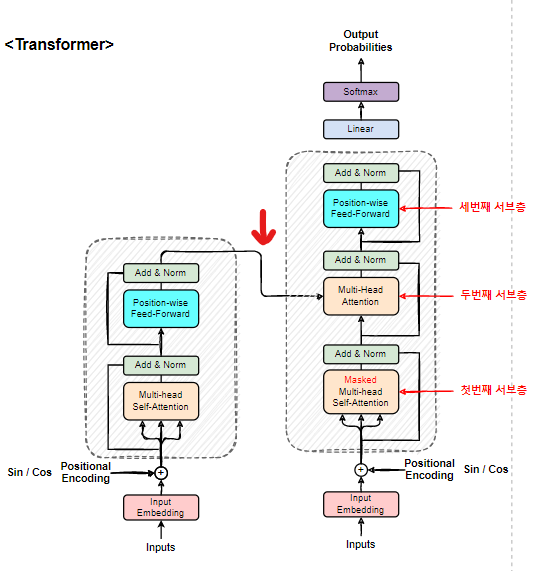
하지만 그 전에
디코더층에서의
입력값+포지셔널 과정이 끝난 직후
낯선 단어가 포함된
Attention Layer가 보인다.
✨ Masking 작업 ✨
Transformer에서
마스킹이란 단어는
가리다라는 뜻이 있는데,
이때 가리는 역할로
<pad> 토큰에 # 부족한 길이의 공간
-1e9라는 아주 작은 음수를 곱한다.
이렇게 하는 이유는
아주 작은 음수 # -무한대와 같은 수를
곱해주면
어텐션 스코어 함수가
Value와 곱해지기전,
즉. 소프트 맥스를 지날때,
해당 위치의 값이
0이 되어 단어 간 유사도를 구하는 일에
<pad>토큰이 반영되지 않는다.
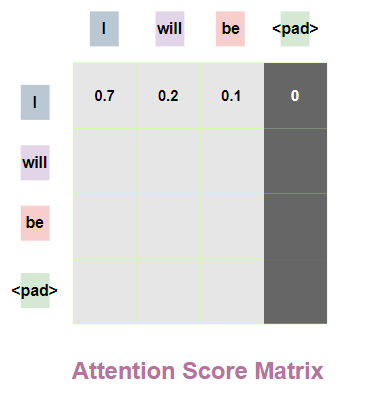
이를 통해 인코더에 들어온 문장의 길이와
디코더에 들어온 문장의 길이가 달라도
문제 없이 계산할 수 있다.
다음은 인코더층에서 보았던 것처럼
인코더 연산이 끝난 후 디코더 또한 num_layers만큼연산이 시작 되는데,
디코더의 두번 째 서브층에서 인코더층에서 나온 출력(행렬)을 전달 받는다.
이때의 인코더 층에서 나온 출력(행렬)을 통해각 위치의 단어를 예측하도록 훈련한다.
# 인코더가 보낸 출력을 각 디코더 층 연산에 사용한다.
💡 룩-어헤드 마스크(look-ahead mask)
디코더는 문장 행렬로 입력을 한번에 받으므로
# Transformer는 교사 강요(Teacher Forcing)을 사용하여 훈련
현재 시점(위치)의 단어를 예측하고자 할때
입력 문장 행렬로부터 미래 시점의 단어까지도
참고할 수 있는 현상이 발생
때문에 현재 시점(위치)의 예측에서
현재 시점보다 미래에 있는 단어들을
참고하지 못하도록
룩-어헤드 마스크(look-ahead mask)를 도입했습니다.
때문에 룩-어헤드 마스크(look-ahead mask)는
디코더의 첫번째 서브층에서 이루어진다.
그림 으로 쉽게 표현하면 아래와 같다.
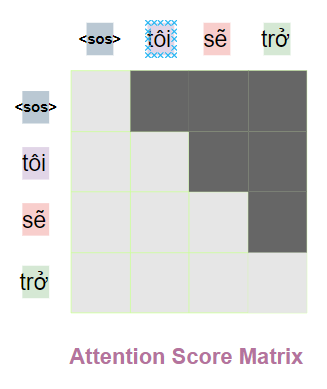
마스킹의 위치를 보면
자기 자신과 그 이전 단어들만
참고 할 수 있음을 알 수 있다.
트랜스 포머에서는 총 세가지 어텐션이 존재하며
모두 멀티 헤드 어텐션을 수행하고
스케일드 닷 프로덕트 어텐션 함수를 호출한다.
각 어텐션 메커니즘에서
함수에 전달하는 마스킹을 정리하면
아래와 같다. ⭐⭐⭐⭐⭐
- 인코더의 셀프 어텐션 : 패딩 마스크를 전달
- 디코더의 첫번째 서브층인 마스크드 셀프 어텐션 : 룩-어헤드 마스크를 전달
- 디코더의 두번째 서브층인 인코더-디코더 셀프 어텐션 : 패딩 마스크를 전달
마지막 세번째 층은 인코더 층과 같이
FFNN층을 거치고
그 다음 잔차연결 및 정규화를 거쳐
Transformer의 최종 출력값이 나온다.
'Hello MLop > DL' 카테고리의 다른 글
| Stable Diffusion (0) | 2023.02.22 |
|---|---|
| NLP_어텐션 메커니즘(Attention Mechanism) (0) | 2023.01.23 |
| NLP_RNN을 이용한 Encoder-Decoder (0) | 2023.01.23 |
| MLop_DL_LSTM 실습 (0) | 2022.12.18 |
| MLop_DL_RNN 실습 (0) | 2022.12.17 |



