20221107
20일 차

머신러닝 수업 1일차
기본적인 과정을 끝마치고 프로젝트도 해보고
머신러닝의 세계로 발을 딛었다.
1일차라 간단하게 insurance.csv를 가지고 맛만 보는 시간을 가졌다.

처음으로 해보는 방식은 선형회귀를 통해 실습해 보았다.

중요 라이브러리를 import해주고
file_name에 실제 파일 이름을 변수로 저장
주소는 url이라는 변수에 저장 후
f 스트링을 통해 file_name을 넣어주고
pd.read_csv()를 통해 데이터를 확인해 보았다.

.head()를 해본 결과 데이터가 잘 나온것을 확인할 수 있었다.

.info()로 결측치 확인과 데이터 타입, 컬럼명을 확인하고

.describe()를 통해 각 컬럼별 데이터값의 통계량을 보았다.
* 판다스의 숫자 데이터를 소숫점 n자리 까지만 표시하기 위해

범주형 데이터를 전처리 하기 위해
사이키런(sklearn)에서 선형회귀(LinearRegression)를 임포트 해주고
독립변수와 종속변수를 나누어
저장하려고 하자 오류가 났다.

그 이유는 컬럼 'sex' 와 'smoker','region'이 데이터 값을 object를 가지기 때문이다.
때문에 우린 이를 수치화 해줘야 하는데,

흡연여부를 나타내는 smoker 컬럼의 경우는 흡연 한다 or 안한다로 나타낼 수 있기 때문에
df.smoker == 'yes'로 bool타입을 통해
값을 True or False로 나타내고
bool타입은 0과 1로 나타내기 때문에
.mul(1)을 하면?


위와 같이 1과 0으로 이루어진 column으로 바꿀 수 있다.
* 마무리로 smoker 컬럼을 재 정의 해준다.

이제 남은 두 컬럼 'sex'와 'region'이 남았는데
이 두 컬럼은 bool타입으로 바꾸긴 난해한 컬럼이다.
성별을 True 와 False로 볼 수 없으며
region(지역)은 총 4개로 구성되어 있기 때문이다.

이런 경우 .get_dummies 메서드를 쓰면
자동으로 각각의 컬럼들을 1,0으로 나누어 준다.
* 결측치가 없기 때문에 .get_dummies 사용
* 결측치가 존재 하는 컬럼일 경우 없앨지, 살릴지 선택해야함.
* 만약 살린다면 결측치를 채워주고 변환 가능
위의 데이터 프레임을 보면
.get_dummies() 를 사용한 댓가로
컬럼 갯수가 11개로 늘어나고
그에 따라 로우 갯수가 1338개로 늘어난 것을 알 수 있다.
따라서 효율적 계산과 처리를 위해
컬럼 갯수를 줄여야 하는데
성별(sex)의 경우 남자 아니면 여자 이기 때문에 둘 중 하나만 써도 되고
지역(region)의 경우 결측치가 없기 때문에
한 장소가 1이면 다른 세 장소가 0 이므로 한 장소를 없앨 수 있다.
이런 경우 get_dummies()안에 drop_first=True를 추가해주면 된다.

실행 한 결과 위의 컬럼이 11개에서 9개로 줄었으므로
데이터 또한 약 2650개 정도 줄어든 것을 확인할 수 있다.

그럼 이제 비교하기 위한 데이터 전처리 과정이 끝났으니
러닝을 하기 위한 전처리를 해보자.

df_dummy의 컬럼중 expenses를 제외한 컬럼들을 X (독립변수)로 저장하고
y= df_dummy.expenses(종속변수) 로 저장했다.
* 우리가 비교하려는 컬럼이 보험료에 얼마나 영향을 미치는가? 이기 때문

그리고 사이키런에서 train_test_split을 import 해
러닝 준비를 시킨다.

독립 변수 X 와 종속 변수 y를 이용해
연습할 독립 변수 X_train 연습할 종속변수 y_train 과
시험을 치룰 독립 변수 X_test 시험을 치룰 종속변수 y_test를 만들고
test_size를 정하고random_state 로 seed값을 임의로 만든다.

사이키런에서 import 선형회귀(LinearRegression)를 해주고
model에 X_train, y_train을 설정하여 러닝 준비를 끝낸다.

pred라는 변수에 model.predict()를 사용하여
X_test의 예측값을 저장하고 이제 비교를 해보자.

comparison, 즉 비교라는 뜻을 가진 변수에DataFrame을 생성해 준다.컬럼은 'actual'에 y_test값, 'pred' 에 pred(X_test)를 넣어준다.
위의 사진을 보면 값이 차이가 많이 나는것을 알 수 있다.

좀 더 이 수치를 이해하기 쉽게 시각화를 해봐야 하는데
matplotlib.pyplot과 seaborn을 이용해 시각화 툴을 임포트 해준다.
그리고 위와 같이 x축명에 'axtual' 을, y축명에 'pred'을 대입해주고
data = comparison을 써주면
위와 같은 산점도 형식으로 그래프가 나온다.
시각화된 그래프를 보더라도 뭔가 일치하는 그래프의 모양은 아닌걸로 보아
러닝 결과가 바람직 하지 못하다는것을 알 수 있다.

이렇게 선형회귀분석에서 기준치와의 오차가 심한경우
MSE(평균제곱오차)
RMSE(평균오차)R² (결정계수)
세 가지의 데이터로 비교해 얼마나 오차가 심한지도 판단이 가능하다.
✔ MSE (평균제곱오차)
오차(잔차)의 제곱에 대한 평균을 취한 값
- 실제값(관측값)과 추정값과의 차이. 즉 오차가 얼마인가를 알려주는데 많이 사용되는 척도
* MSE가 작을수록 추정의 정확성이 높아짐
✔ RMSE(평균오차)
- MSE의 제곱근
✔ R² (결정계수)
- 회귀식이 얼마나 정확한지를 나타내는 숫자 (0≦R²≦1)
* R² =0 신뢰할 수 없다.
* R² =0.5 어느정도 신뢰한다.
* R² =1 신뢰할만하다.
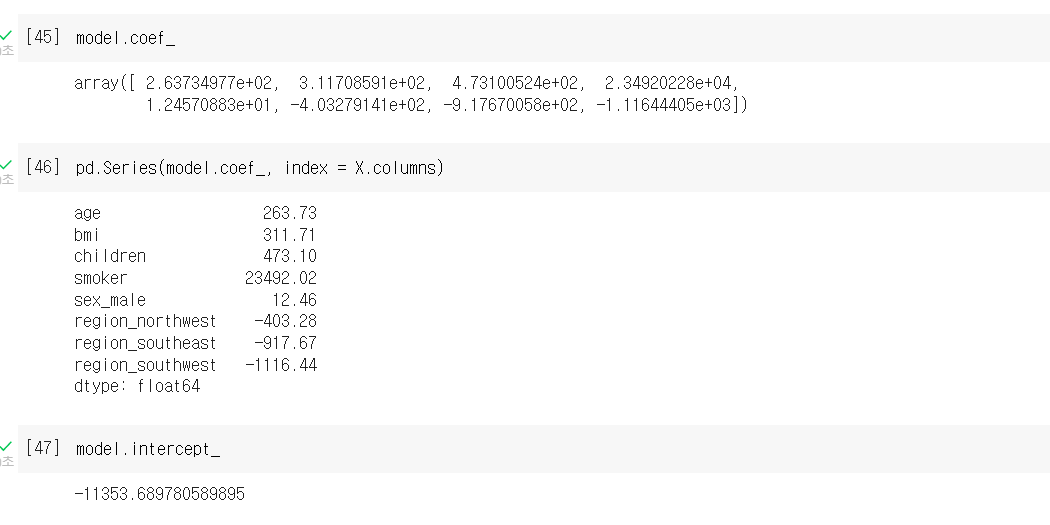
.coef_는 기울기를 구하는 메서드 인데
선형회귀분석에서 기울기를 구해 그 차이를 보는 정도로 오차가 얼마나 났는지 추측할 수 있다.
.intercept_는 절편을 구하는 메서드 인데
기울기와 절편을 이용해 x절편 y절편을 구할 수 있다.

마지막으로 우리가 만든 것을 모델로 배포 하는 과정이다.
joblib를 import해 .pkl로 저장시켜 배포 할 수 있다.
'Hello MLop > ML' 카테고리의 다른 글
| MLop_ML_RandomForest_중고차 가격 예측 (0) | 2022.11.15 |
|---|---|
| MLop_ML_DecisionTree_급여 예측 분류 (0) | 2022.11.13 |
| MLop_ML_NaiveBayes_SMS 스팸 수집 (0) | 2022.11.12 |
| MLop_ML_KNN_WineData (0) | 2022.11.10 |
| MLop_ML_로지스틱회귀_타이타닉 생존자 예측 (0) | 2022.11.09 |



