20221109
22일 차

오늘 적용할 모델은 NaiveBayes이다.
데이터는 kaggle에서 SMS Spam Collection Dataset을 가져왔다.
들어가기 앞서 Naive Bayes에 대해 알아보자.
Naïve Bayes Classification란?
사전적 의미 : 특성들 사이의 독립을 가정하는 베이즈 정리를 적용한 확률 분류기
Naïve의 사전적 의미 = '(모자랄 정도로) 순진한'
사전적 의미를 덧붙여 해석하면 그냥 단순하고 순수하게 Bayes분석을 한다로 볼 수 있다.
왜 이런 뜻이 됐을까?
그 이유는 분류를 쉽고 빠르게 하기 위해 분류기에 사용하는 특징(feature)들이 서로 확률적으로 독립이라는 순수함이 가정으로 들어갔기 때문이다.
예를 들어 타이타닉 생존자 예측에서 생존률이 알고 싶을때 주어진 중요한 변수들이 몇 가지 있었다.'나이', '이름', '성별' 등과 같이 변수들간의 연관관계가 결과에 영향을 끼칠것 같은(독립적이지 않을것 같은) 변수들은우리가 조금 더 정답을 맞출 확률을 높히기위해 전처리에 신경을 쓴다.
하지만 나이브베이즈는 이러한 특징(변수)들을 단순화 시켜 쉽고 빠르게 판단을 내릴 때 주로 사용된다.
ex) 문서 분류, 질병 진단, 스팸 메일 분류
Naive Bayes의 장점과 단점
⭕ 장점
그룹이 여러 개 있을때 쉽고 빠르게 예측 가능로지스틱 회기분석같은 방식보다 학습 데이터가 적게 필요 # 독립이라는 가정이 유효하다면
❌ 단점
독립이라는 가정이 성립하지 않거나 약하면 결과에 에러발생할 수 있음 실제로는 완전하게 독립적인 상황이 많지 않음
이제 분석해보자.
✨ 데이터 불러오기 ~ 전처리 전

.head()로 확인

스팸 문자 판독이기 때문에
전무 문자내용이 데이터로 들어왔고
당연히 데이터 타입은 object이며
결측치 또한 없었다.
'target'컬럼은 'text'컬럼의 내용이
스팸문자이냐 (spam), not스팸문자(ham)이냐로 나눴다.
✨전처리

파이썬의 특성상 good도 문자열, good! 도 문자열로 볼것이기에
원하는 데이터를 얻기 위해 특수 문자를 제거해 줘야한다.

string을 임포트 해주고string.punctuation 을 해주면 파이썬에서의 특수문자들이 나온다.
그럼 위의 전체 데이터에서 행별로 조회하여(.loc[0]) 0번째 데이터를
first_text라는 변수에 저장하고 특수 문자를 없애보자.
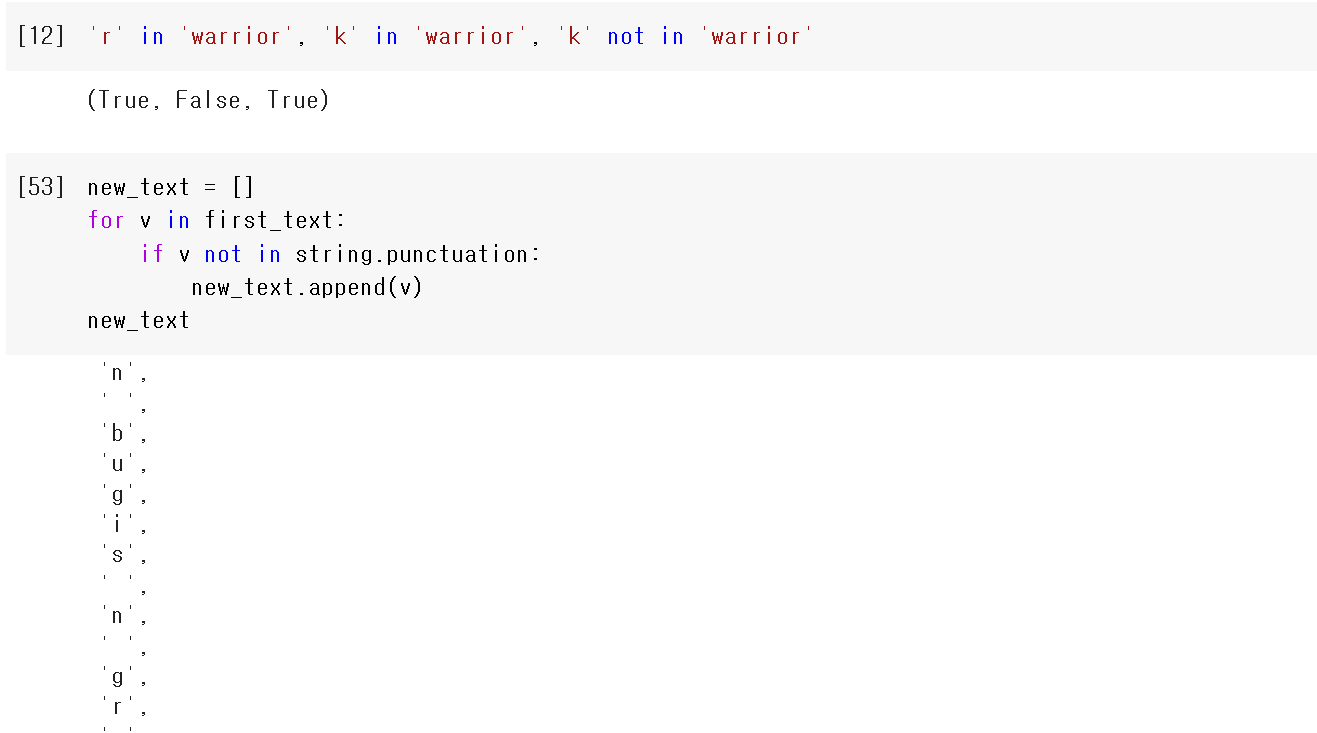
위의 코드 처럼 in을 이용해 True, False 값을 받을 수 있는데
이를 활용해서 조건문 if에 적용시키면
new_text 리스트에 문자열이 차례대로 들어가는 것을 볼 수 있다.

하지만 원하는건 단어 형태이니
""문자열에 new_text를 넣어주면
위와 같이 특수문자가 제외된 문장이 들어가게 된다.
💡 리스트 컴프리핸션을 사용하여 코드를 짠 경우

해석
""에 .join할거야 ()를
()는 c야 반복문(for)에서 차례대로 들어간
c에 차례대로 들어가는 것들은 new_text의 0번부터 마지막까지야
근데 조건(if)이 있어
c는 특수문자(string.punctuation)가 안들어가야돼(not in)
즉, new_text의 0번부터 마지막 자료중c가 되는건 특수문자는 아니야
그럼 연습해서 만들어본 이 리스트컴프리핸션으로
전체를 바꾸기 위해 함수를 선언해보자.
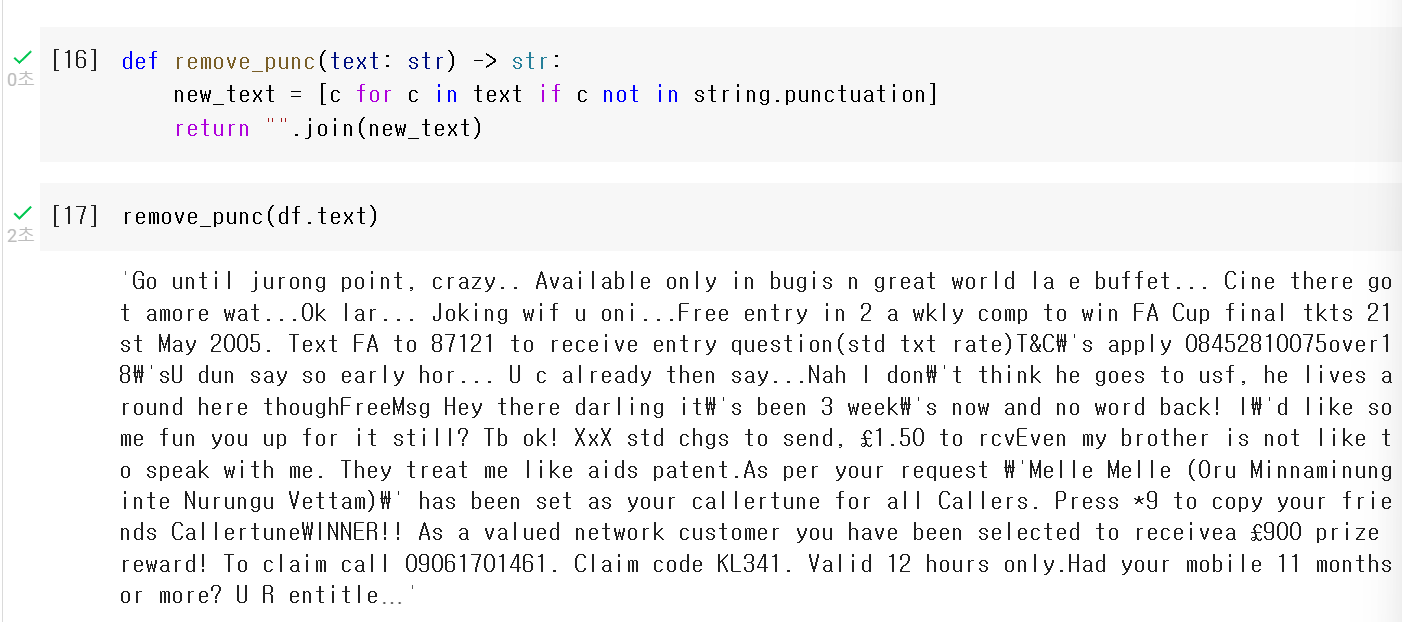
위와 같이 선언한 remove_punc함수에 df.text(text 컬럼)을 넣어주면
모든 시리즈 데이터가 특수문자가 제외된 채로
한줄로 쭈욱~ 들어간 것을 확인할 수 있다.

하지만 한 줄로 있어 보기 불편하니
.apply를 이용해 각각의 데이터에 적용시켜 보자.
💡 df / df.column 행별로 어떠한 함수를 적용하고 싶다. → .apply
적용시키면 원하는 모양으로 데이터가 저장된것을 알 수 있다.

💡 불용어(Stopword)란?
인터넷 검색 시 검색 용어로 사용하지 않는 단어. 관사, 전치사, 조사, 접속사 등은 검색 색인 단어로 의미가 없는 단어이다.

불용어 처리를 하기위해
불용어를 불러와야 한다.
nltk를 import해주고
'stopwords'를 다운로드 해준다
nltk.corpus(말뭉치)라이브러리에서 'stopwords'(불용어)를 불러오면
우리는 영어의 불용어가 필요하기 때문에stopwords.words('english') 를 입력하면 위와 같이 영어 불용어가 출력된다.

그럼 전체 데이터에 불용어를 빼주기 위해 위의 특수문자 뺀것처럼 반복문을 돌려주면
출력과 같이 불용어가 빠진 상태로 나오는것을 확인할 수 있다.

다음으로 remove_stop_words라는 불용어를 빼주는 함수를 선언하고
❗stop_english = stopwords.words('english')
df.text에 .apply(remove_stop_words)해주면?
불용어가 빠진 데이터를 받을 수 있다.
💡 df.text는 이제 특수문자와 불용어가 제거된 데이터이다.

이제 확인 및 비교를 위해
df.text의 데이터가 스팸인지 스팸이 아닌지
'ham' 과 'spam'으로 df.target에 저장되어있는데
df.target의 데이터를 'spam'이면 1, 'ham'이면 0으로 바꿔주자.


x = df.texty = df.target 으로 저장하고

사이키런에서 CountVextorizer를 불러오고
cv에 클래스로 저장해 준다.cv에 x데이터를 fit(훈련)시키면
cv.vocabulary_를 입력 시키면x데이터(df.text)속의 단어에 vocabulary_ 의 단어별 번호가 같이 매칭되어 나온다.
이제 transform해주자

위의 코드를 저장하면
(0, 1187) 1 → 0번째 데이터에 1187이라는 단어가 1개 있다.
로 쭉 출력된다.

그럼 이제 훈련과 시험셋을 나눠서 러닝을 시켜보자.

사이키런의 나이브베이즈 라이브러리에서 모델이 될 MultinomialNB를 임포트 해준다.
MultinomialNB는 나이브 베이즈에서 빈도수를 구할 때 사용한다.

그리고 accuacy_score, confusion_matrix 또한 임포트해서
테스트셋들의 결과를 보자.
accuacy_score

전체문제에서 맞춘문제가
98%의 정확도를 보이는것을 확인할 수 있다.
confusion_matrix

선형회귀 분석과 달리 라이브베이즈는
어떤 오차에 관하여 어떻게 얼마나 뭐가 났는지 알기 어렵다.
그래서 confusion_matrix(혼동행렬)를 통해 값과 시각화를 만들어
좀 더 직관적인 결과를 볼 수 있다.
confusion_matrix 시각화

True Positive(TP) : 실제 True인 정답을 True라고 예측 (정답)
False Positive(FP) : 실제 False인 정답을 True라고 예측 (오답)
False Negative(FN) : 실제 True인 정답을 False라고 예측 (오답)
True Negative(TN) : 실제 False인 정답을 False라고 예측 (정답)
즉 위의 시각화를 해석하면
TP: Spam을 Spam으로
TN: Spam을 Ham으로
FP: Ham을 Ham으로
FN: Ham을 Spam으로
해석할 수 있다.
'Hello MLop > ML' 카테고리의 다른 글
| MLop_ML_RandomForest_중고차 가격 예측 (0) | 2022.11.15 |
|---|---|
| MLop_ML_DecisionTree_급여 예측 분류 (0) | 2022.11.13 |
| MLop_ML_KNN_WineData (0) | 2022.11.10 |
| MLop_ML_로지스틱회귀_타이타닉 생존자 예측 (0) | 2022.11.09 |
| MLop_ML_선형회귀_보험료 예측 (0) | 2022.11.07 |



