20221108
21일차

이번에 해볼것은 kaggle의 WindData에 KNN알고리즘을 적용시켜 보겠다.
KNN 알고리즘이란?

내가 잘 이해했다면 KNN알고리즘은 다음과 같다고 생각한다.
"원안에 누가 많아? 이게 많아? 그럼 너는 이거일 확률이 높아." 이다.
조금 학술적인 단어를 추가하면
데이터로부터 거리가 가까운 'K'개의 다른 데이터의 레이블을 참조하여 분류하는 알고리즘으로
거리를 측정할 때 '유클리디안 거리' 계산법을 사용한다.

💡 한가지 Tip은
원안에 들어오는 비교할 데이터 개수를 K개라고 할때
보통 홀수로 지정하는게 좋다.
왜냐하면 짝수일 경우
반반의 확률이 나올 수 있기 때문이다.
❗ 주의할 점
거리기반 모델이기 때문에 표준화가 필요함.
💡 정규화 적용(=스케일링)
▶ 최소 - 최대 정규화, z-점수 표준화)
이제 WineData를 가져와서 적용해보자.
임포트 및 데이터 불러오기 데이터 확인 과정은자주 했으니 별 코멘트 없이 넘어가겠다.



아주 운이 좋게? 결측치가 존재 하지 않으며
전부 숫자형 데이터인것을 확인 할 수 있다.
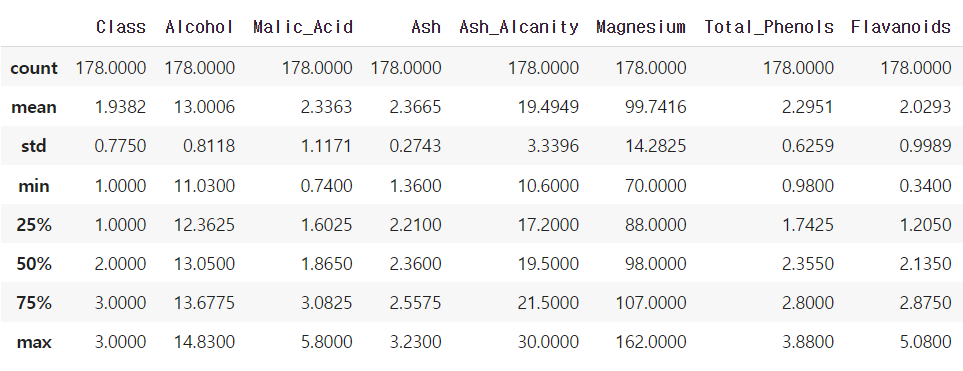
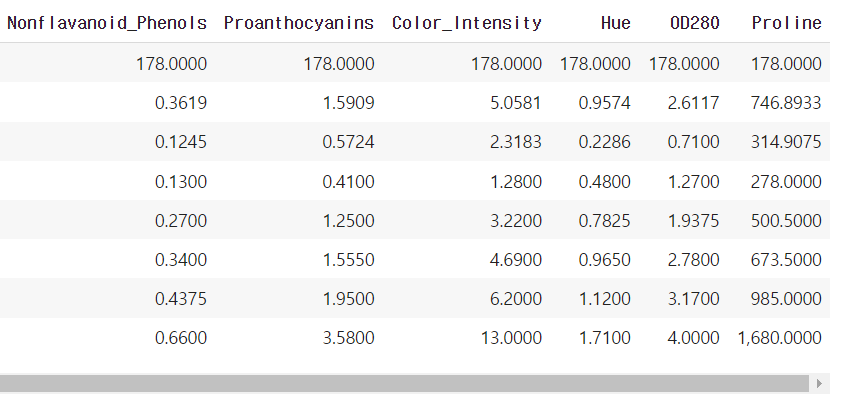
KNN 알고리즘을 사용할때는 개인적으로.describe()가 중요하다고 생각한다.
왜냐하면 데이터 값이 표준화가 되야 쓸 수 있기 때문이다.
❗ 특히 이상치 존재에 신경 쓰자
위의 데이터는 특별히 이상치가 존재하지 않는것 같다.
하지만 데이터의 값의 범주가 다 다르므로 표준화를 해줘야 한다.
사이키런(sklearn)에 데이터를 표준화 시켜주는,
즉 스케일링 해주는 구조체(class)를 임포트 해주자.


스케일링은 간단히 설명하면
데이터의 범위를 맞추는 작업 이다.
= 표준화
Min-Max Scaling (최소-최대 스케일링)을 사용하여
와인데이터 분포의 특성을 최대한 살리고 유지할 수 있는 장점을 살려보자.


.fit()은 교육시키다 라는 뜻을 가진다.
.transform() 은 형태를 바꿔준다 라는 의미다.
그럼 .fit_transform()은 괄호 안의 매개 변수를 가르치고 형태를 바꿔주는걸 동시에 한다는 것이다.
💡 많은 사람들이 헷갈려 한 부분인데
위의 코드는
변수(mm_scaled) = ▶ 변수에 저장 하겠다.
mm_scaler = MinMaxScaler() ▶ 최대최소 스케일링 시켜줄게
.fit_transform(df) ▶ df를 근거로 앞에거를 훈련시키고 형태를 바꿔줄게.
# 앞에 .(점)이 붙으면 앞에거를 뒤에거로 해줄게란 뜻임
그럼 연결 시켜보면
mm_scaled = mm_scaler.fit_transform(df)
변수(mm_scaled)에 저장 할게 # 정확하게 말하면 주소를 저장할게
df를 근거로
MinMaxScaler()에
훈련(fit)도 시키고 형태도 바꿔(transform)주는 기능을
=>
df_mm_scaled를 만들건데
데이터 프레임으로 만들거야mm_scaled란 데이터를 자료로 쓸거고컬럼명은 df의 컬럼명을 쓸거야.

출력을 했더니 위와 같은 결과가 나온다.
스케일링한 값들이 데이터로 들어갔으므로
전부 1과 0사이의 데이터가 되었다.
스케일링 끝났으니 전처리도 끝.
이제 그냥 결과만 도출하면 된다.

훈련셋과 시험셋 분리하고
X훈련셋과 X시험셋 스케일링된 변수로 저장
❗ X_train은 mm_scaler에게 훈련(fit) 시키는데 왜 X_test는 그냥 transform만 하냐?
X_train을 근거로 이미 두 번재 줄에서 mm_scaler에게 훈련 시켰으므로
X_test를 스케일링 할때는 코드에 있는 mm_scaler에 훈련을 시키면 안된다.
만약 X_test에도 fit을 넣으면 세번째줄의 mm_scaler는 중첩 학습이 된다.
그럼 두 값은 비교를 못함

그럼 이제 사이키런에서 KNeighborsClassifier를 임포트하고
knn에 클래스 형태로 저장한다음
knn을 X_train_scaled와 y_train을 근거로 학습 시키고
pred란 변수에
를 저장한다.
❗ 너무 복잡하게 생각하지 말고 뒤에서 부터 차근차근 앞으로 연결시켜 해석해보자.

pred가 잘 나오는지 확인해보자.
와인등급이 총 3개 였으므로 잘나옴.

정확도는 88프로가 나왔다.
하지만 기본적으로 KNN에서 예측에 참고할 이웃 수는 기본적으로 5개로 고정되어 있는데
이를 변수로 놓고 결과를 확인할 수 있는 함수를 선언해 준다면?


위와 같이 n(원안에 몇 개)이 몇 일때
최고의 확률이 나오는지 확인할 수 있다.
'Hello MLop > ML' 카테고리의 다른 글
| MLop_ML_RandomForest_중고차 가격 예측 (0) | 2022.11.15 |
|---|---|
| MLop_ML_DecisionTree_급여 예측 분류 (0) | 2022.11.13 |
| MLop_ML_NaiveBayes_SMS 스팸 수집 (0) | 2022.11.12 |
| MLop_ML_로지스틱회귀_타이타닉 생존자 예측 (0) | 2022.11.09 |
| MLop_ML_선형회귀_보험료 예측 (0) | 2022.11.07 |



