20221115
28일차

오늘 할 실습은 LightGBM을 활용한 신용카드 이상거래 예측이다.
데이터는 kaggle에서 가져왔으며
간단한 데이터 세트는 이러하다.

LightGBM (Light Gradient-Boosting Machine)?
Microsoft 에서 개발한 머신 러닝용 분산 그래디언트 부스팅 모델이다.결정 트리 알고리즘을 기반으로 만들어졌다.
XGBoost의 많은 장점을 가지고 있는데이 둘의 가장 큰 차이점은 트리 구성에 있다.
LightGBM은 대부분의 다른 구현처럼 트리를 레벨별로(행 단위로) 성장시키지 않는다.
아래 사진을 보자

왼쪽의 Leaf-Wise Growth가 LightGBM의 경우인데 오른쪽에 비해 leaf-node로 확장되는것을 볼 수 있다.
때문에 XGBoost보다 학습하는 속도가 빠르다
💡 LightGBM 장점
1. 학습하는 속도 빠름2. 높은 정확도3. 예측에 영향을 미친 변수의 중요도 확인 가능4. GPU 학습 지원5. 데이터set가 클수록 더 좋은 효율 보여줌
💡 LightGBM 단점
1. 해석이 어려움
2. 하이퍼 파라미터 튜닝 까다로움
데이터를 불러오자!
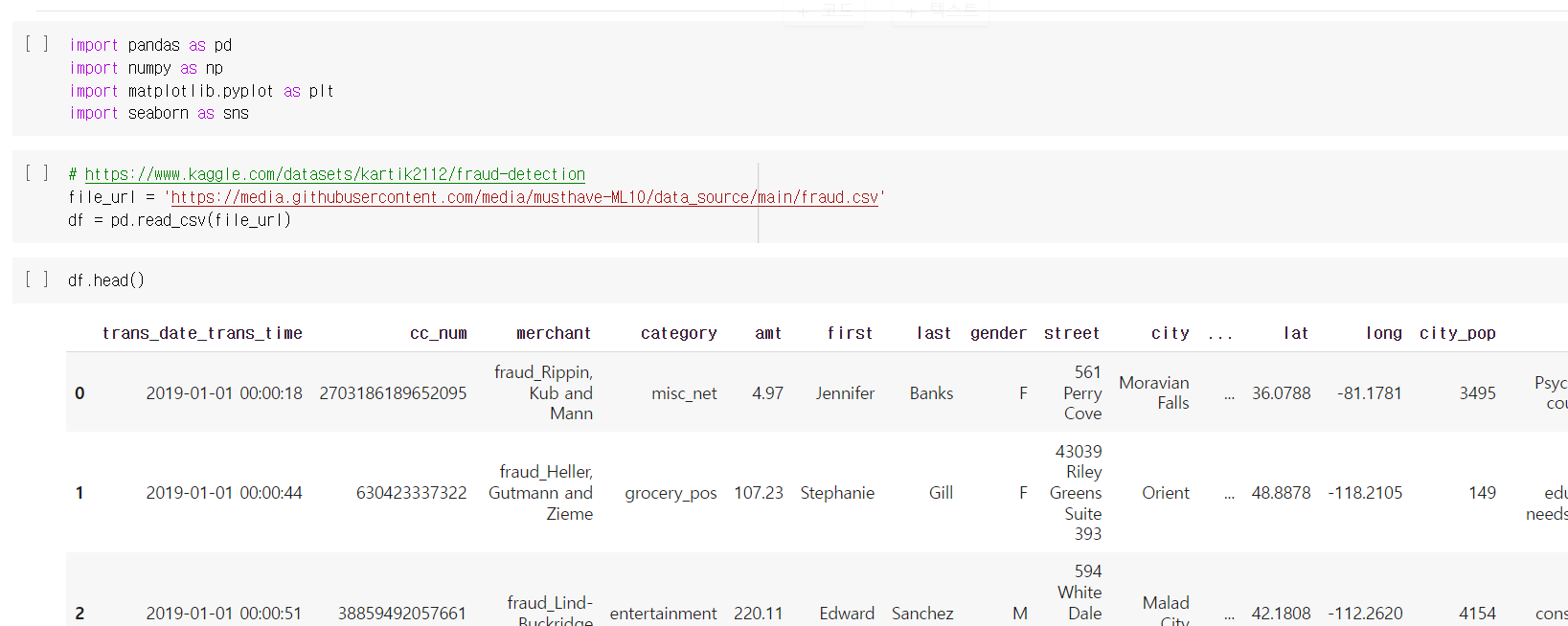

데이터 컬럼은 위와 같이 22개가 존재했다.

각 컬럼의 설명이다.
종속 변수는 'is_fraud' (이상거래 여부) 로 정했다.

컬럼의 개수가 많으면 결측치가 보이지 않는데
이때 .info(show_counts=True) 를 해주면 결측치 정보가 보이게 된다.
다행히 결측치가 없다는것을 확인했다.
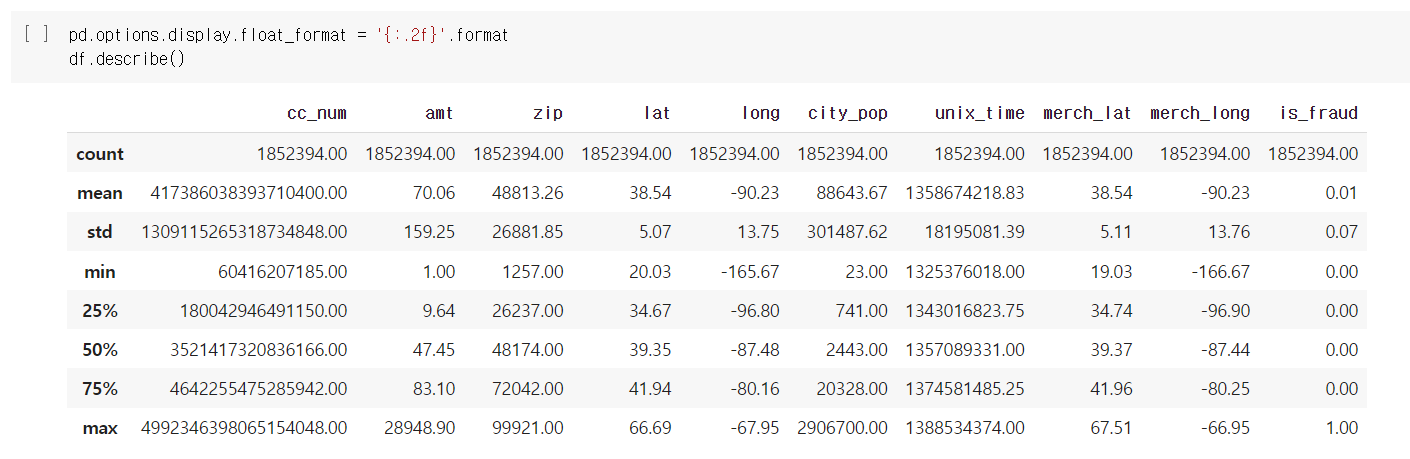
.describe()도 확인해 준다.
전처리로 가보자.

가장 먼저 종속변수에 영향을 줄것 같지 않은 독립 변수들을 drop해 주었다.

위의 info를 보면
'trans_date_trans_time'컬럼이 object 타입인데
이를 진짜 날짜로 인식시키기위해 .to_datetime한 과정이다.

피처 엔지니어링은 원래 고객의 거래 패턴에서 벗어나는 거래를 찾아 저장해 줄것이다.

💡 Z - score (표준화 점수)
통계학적으로 정규분포를 만들고 개개의 경우가
표준편차상에 어떤 위치를 차지하는지를 보여주는 차원없는 수치이다.
표준화 점수를 만들기 위해
우리는 평균과 표준편차 값이 필요하다.
그래서 group_by를 이용해 'cc_num'별 amt의 mean 과 std를 구해준다.
그럼 이제 merge를 이용하여 원본 데이터에 합쳐주기 위해
group_by한 데이터 프레임을 저장해주고 인덱스를 삭제해 준다.

원본 데이터프레임 df에서 'cc_num','amt','mean','std' 컬럼을 조회해주는 장면이다.
그럼 이제
X - 평균 / 표준편차 = Z- score이기 때문에
각 컬럼끼리 계산해주고 저장해주면?

위와 같이 고객별 거래금액의 Z-score가 탄생하게 되는것이다.

이제 필요 없어진 고객별 거래금액의 평균과 표준편차 컬럼은 삭제해준다.

이번엔 범주별 결제금액을 구해주는 과정이다.
우리가 알고 싶은 내용은 고객별로 어느 카테고리에서 원래 소비에서 벗어나게
소비를 했냐를 체크해서 이상거래를 판단하는데 도움이 되는 데이터를 만들고 싶다.
우선 다시 고객과 카테고리별 금액의 평균과 표준편차를 만들어준다.

merge를 진행하고 컬럼 확인을 해주었다.앞서 한 과정과 별 차이 없기에 자세한 설명은 생략하겠다.

고객별 카테고리의 Z-score가 만들어 진것을 확인할 수 있다.그리고 역시 필요없는 평균과 표준편차 컬럼은 삭제해 주었다.
위의 데이터를 보니 위도와 경도 즉 위치 데이터가 나와있는데
이러한 범주형 데이터를 만약 고객의 위치가 평소 위치와 크게 벗어나 있고거기서 평소와 다른 금액이 결제 되었다면 이는 이상거래라고 판단하는 것이다.

geopy.distance를 import해주고
상점의 위치관련 데이터 및 고객의 위치관련 데이터를 컬럼으로 만들어주고
위치데이터가 신규로 생성 될때는 데이터 프레임에 넣기 위해 Series로 만들어준다.
그럼 이제 'distance'컬럼을 만들고 apply.(lambda 함수)를 이용해 상점의 좌표와 고객의 좌표간의 거리를 저장해준다.

df2에 df를 copy() 해주고
'distance' 컬럼을 한번 출력해보자.
❗ 마지막에 apply(lambda함수)사용시 .km를 빼먹으면 단위를 빼먹기 때문에 다시 float으로 변환해줘야함

이제 'distance_info'에 z-score작업을 위해 group_by 해준다.

이제 Merge ▶ Z-score구해서 저장 ▶ 필요없어진 컬럼 삭제
완료!

결측치 체크해보고 이상 없다는것을 확인

'dob'컬럼은 카드주인의 생년월일을 나타낸 컬럼이다.
이를 나이로 바꿔주는 전처리를 해보자.
'dob'의 데이터를 to_daetime화 해준다.

그럼 이 데이터를 연도만 표시해주기 위해 dt.year처리를 해준다.
마지막으로 'age'컬럼에 만 나이를 넣기위해 (현재 년도-1) - pd.to_datetime(df['dob']).dt.year # 연도만 나온 데이터
출력 시키면?

위와 같이 'age'컬럼에 만 나이가 들어감을 확인 할 수 있다.
그리고 이제까지 재료료 쓰였던 'cc_num'컬럼부터 필요없어진 'cust_coord' 컬럼을 삭제해준다.

마지막으로 'category' 와 'gender'컬럼을 get_dummies화 해주고 drop_first=True 해준다.
우리는 과거의 데이터를 통해 미래를 예측해야하기 때문에
날짜를 인덱스로 만들고 훈련셋과 시험셋을 나눠주는 작업을 해야한다.

.set_index로 'trans_date_trans_time'을 해주고
df의 인덱스를 확인해 본다.

train과 test로 df을 인덱스를 기준으로 나눠준다.
X_train에는 train 데이터에서 'is_fraud'컬럼을 열방향으로 drop해주고y_train에는 train 데이터에서 'is_fraud' 컬럼으로 저장해준다.
test 데이터 또한 위의 규칙과 같이 만들어준다.

lightgbm을 임포트 해주고
모델링 해주고
accuracy_score도 임포트 해줘서
결과를 확인해준다.
💡 1 - df.is_fraud.mean() 하는 이유
'is_fraud' 컬럼의 values들은 현재 이상거래가 났냐(1) 안났냐(0)를
0 ~ 1까지의 수치로 하여 고객별로 저장해 놓은 컬럼이다.
그래서 1에서 'is_fraud'컬럼의 평균을 빼주면
이상거래가 안난(0) 사람들의 비중을 보여준다.
때문에 구별하는 모델의
정확도(accuracy_score) 와 이상거래 유무비중 데이터(1 - df.is_fraud.mean())를 비교하면
머신러닝 모델을 잘 구현 했는지 확인 할 수 있다.
하지만 위의 모델의 결론은 차이가 많이 없기 때문에
우리는 이제 미세한 조정을 하기위한 데이터를 보기로 한다.

결과를 분석하기위해 3가지의 모듈객체를 import 해주자
우선 혼동행렬(confusion_matrix)을 보자.

우리가 원했던 종속변수 'is_fraud' 는 이상거래여부를 1,0으로 나타낸 것이다.1 = 정상거래 , 0= 이상거래
TN : 이상거래를 이상거래로 보았다.
TP : 정상거래를 정상거래로 보았다.
FP : 이상거래를 정상거래로 보았다.
FN : 정상거래를 이상거래로 보았다.

precision 정밀도

정상거래를 정상거래로 봤을때 이상거래를 정상거래로 얼만큼 봤니
❗ 우리는 정상거래를 1, 이상거래를 0으로 봤기에 혼동에 주의하자.
recall 재현율

정상거래를 정상거래로 봤을때 정상거래를 이상거래로 얼만큼 봤니
F1-score
실제 정상거래를 정상거래로 분류한 것과 정상거래로 분류한것중 실제 정상거래로 분류한것을 고려한 점수
💡 predict_proba
(분류기에서 예측의 불확실성을 추정하는 대표 함수)
decision_function
의 결과 값은 n_samples이며 각 샘플이 하나의 실수 값(임계값)을 반환, 임의의 범위를 가지고 있음
predict_proba
는 각 클래스에 대한 확률(임계값), 항상 0과 1사이의 값을 가짐
예측의 불확실성을 검증하는 대표적인 두 함수는
판단의 기준이된 임계값을 검증하는 것이다.
💡 임계값 ⭐⭐⭐⭐⭐
분류기에서 분류의 기준이 되는 값.
예를 들어 모델을 적용시켜 어떤 종속변수와의 관계에 대해 분류를 시킬때 그 기준이 되는 값.
이진분류의 임계값은 보통 0.5

proba라는 변수에 X_test가 들어간 모델의 predict_proba를 적용시켜 저장한다.
그리고 각각 임계값을 0.2 , 0.8로 나누어 다시 혼동행렬 시각화로 결과를 보자.

임계값이 0.2일 경우
1종 오류(정밀도)는 늘었고 2종 오류(재현도)는 줄은것을 확인할 수 있다.

임계값이 0.8일 경우
1종 오류(정밀도)는 줄었고 2종 오류(재현도)는 늘은것을 확인할 수 있다.
🔥 결론
임계값을 조절해서
정밀도와 재현도의 변화를 보고
전체적인 예측이 잘된것인가 안된것인가 판단할 수 있다.


TPR은 TPRate이다.즉, 실제 1을 얼마나 제대로(1) 예측했냐를 의미한다.
FPR은 FPRate이다.즉, 실제 0인것 중 얼만큼 잘못(1) 예측되었는지 의미한다.
그렇기에 위의 선형 그래프는 TPR축에 가까울수록 좋은 예측 모델임을 의미한다.
💡TPR, TNR, FPR


TPR축에 가까울수록 면적이 넓어지므로
AUC면적은 클수록 좋은 분류기라는 의미이다.

테스트 모델을 roc_auc_score에 넣어주면
현재 분류기는 90점짜리 분류기라는 출력값을 보여준다.
'Hello MLop > ML' 카테고리의 다른 글
| MLop_ML_XGBoost_커플 성사 여부 예측 (0) | 2022.11.17 |
|---|---|
| MLop_ML_RandomForest_중고차 가격 예측 (0) | 2022.11.15 |
| MLop_ML_DecisionTree_급여 예측 분류 (0) | 2022.11.13 |
| MLop_ML_NaiveBayes_SMS 스팸 수집 (0) | 2022.11.12 |
| MLop_ML_KNN_WineData (0) | 2022.11.10 |



